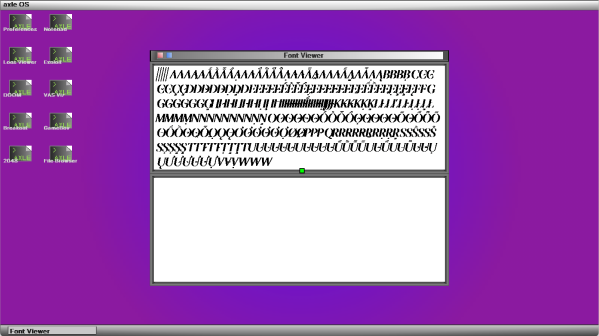
In the wide world of programming, there are a few dark corners that many prefer to avoid and instead leverage the well-vetted libraries that are already there. [Phillip Tennen] is not one of those people, and when the urge came to improve font rendering for his hobby OS, axle, he got to work writing a TrueType font renderer.
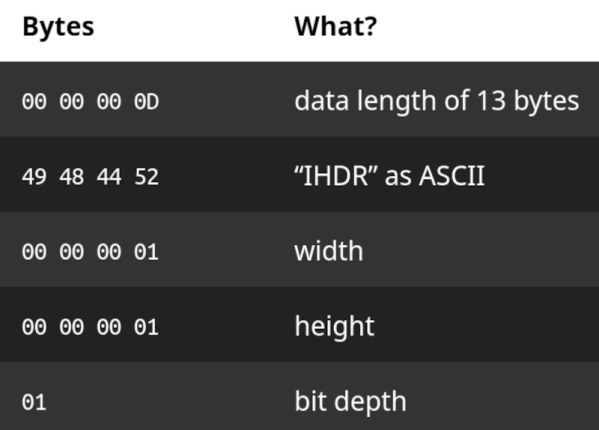
For almost a decade, the OS used a map table encoding all characters as 8×8 bitmaps. While scaling works fine, nonfractional scaling values are hard to read, and fractional scaling values are jagged and blocky. TrueType and font rendering, in general, are often considered dark magic. Font files (.ttf) are structured similarly to Mach-O (the binary format for macOS), with sections containing tagged tables. The font has the concept of glyphs and characters. Glyphs show up on the screen, and characters are the UTF/Unicode values that get translated into glyphs by the font. Three critical tables are glyf (the set of points forming the shape for each glyph), hmtx (how to space the characters), and cmap (how to turn Unicode code points into glyphs).
Seeing the curtain pulled back from the format itself makes it seem easy. In reality, there are all sorts of gotchas along the way. There are multiple types of glyphs, such as polygons, blanks, or compound glyphs. Sometimes, control points in the glyphs need to be inferred. Curves need to be interpolated. Enclosed parts of the polygon need to be filled in. And this doesn’t even get to the hinting system.
Inside many fonts are tiny programs that run on the TrueType VM. When a font is rendered at low enough resolutions, the default control points will lose their curves and become blobs. E’s become C, and D’s become O’s. So, the hinting system allows the font to nudge the control points to better fit on the grid. Of course, [Phillip] goes into even more quirks and details in a wonderful write-up about his learnings. Ultimately, axle has a much better-looking renderer, we get a great afternoon read, and fonts seem a little less like forbidden magic.
Maybe someday [Phillip] will implement other font rendering techniques, such as SDF-based text renderers. But for now, it’s quite the upgrade. The source code is available on GitHub.