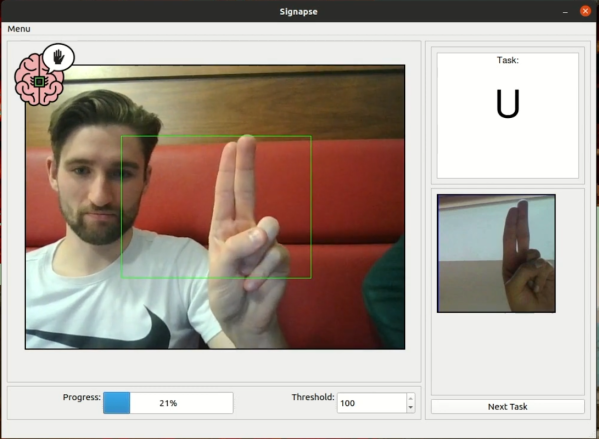
Learning a new language is a great way to exercise the mind and learn about different cultures, and it’s great to have a native speaker around to improve the learning experience. Without one it’s still possible to learn via videos, books, and software though. The task does get much more complicated when trying to learn a language that isn’t spoken, though, like American Sign Language. This project allows users to learn the ASL alphabet with the help of computer vision and some machine learning algorithms.
The build uses a computer vision model in MobileNetV2 which is trained for each sign in the ASL alphabet. A sign is shown to the user on a screen, and the user needs to demonstrate the sign to the computer in order to progress. To do this, OpenCV running on a Raspberry Pi with a PiCamera is used to analyze the frames of the user in real-time. The user is shown pictures of the correct sign, and is rewarded when the correct sign is made.
While this only works for alphabet signs in ASL currently, the team at the University of Glasgow that built this project is planning on expanding it to include other signs as well. We have seen other machines built to teach ASL in the past, like this one which relies on a specialized glove rather than computer vision.
If you live in much of the world today, high-speed Internet is a solved problem. But there are still places where getting connected presents unique challenges. Alphabet, the company that formed from Google, details their experience piping an optical network across the Congo. The project derived from an earlier program — project Loon — that used balloons to replace traditional infrastructure.
Laying cables along the twisting and turning river raises costs significantly, so a wireless approach makes sense. Connecting Brazzaville to Kinshasa using optical techniques isn’t perfect — fog, birds, and other obstructions don’t help. They still managed to pipe 700 terabytes of data in 20 days with over 99.9% reliability.
After a journey of a decade, what started as Project Loon by Google is no more. Promoted as a way to bring communications to the most remote parts of the globe, it used gigantic, high-altitude balloons equipped with communication hardware for air to ground, as well as air to air communication, between individual balloons. Based around LTE technology, it would bring multiple megabit per second data links to both remote areas and disaster zones.
Seven years into its development, Loon became its own company (Loon LLC), and would provide communications to some areas of Kenya, in addition to Sri Lanka in 2015 and Puerto Rico in 2017 after Hurricane Maria. Three years later, in January of 2021, it was announced that Loon LLC would be shutting down operations. By that point it had become apparent that the technology would not be commercially viable, with alternatives including wired internet access having reduced the target market.
While the idea behind Loon sounds simple in theory, it turns out that it was more complicated than just floating up some weather balloon with LTE base stations strapped to them.
Last week we featured a story on the new rules regarding drone identification going into effect in the US. If you missed the article, the short story is that almost all unmanned aircraft will soon need to transmit their position, altitude, speed, and serial number, as well as the position of its operator, likely via WiFi or Bluetooth. The FAA’s rule change isn’t sitting well with Wing, the drone-based delivery subsidiary of megacorporation Alphabet. In their view, local broadcast of flight particulars would be an invasion of privacy, since observers snooping in on Remote ID traffic could, say, infer that a drone going between a pharmacy and a neighbor’s home might mean that someone is sick. They have a point, but how a Google company managed to cut through the thick clouds of irony to complain about privacy concerns and the rise of the surveillance state is mind boggling.
Speaking of regulatory burdens, it appears that getting an amateur radio license is no longer quite the deal that it once was. The Federal Communications Commission has adopted a $35 fee for new amateur radio licenses, license renewals, and changes to existing licenses, like vanity call signs. While $35 isn’t cheap, it’s not the end of the world, and it’s better than the $50 fee that the FCC was originally proposing. Still, it seems a bit steep for something that’s largely automated. In any case, it looks like we’re still good to go with our “$50 Ham” series.
Staying on the topic of amateur radio for a minute, it looks like there will be a new digital mode to explore soon. The change will come when version 2.4.0 of WSJT-X, the program that forms the heart of digital modes like WSPR and FT8, is released. The newcomer is called Q65, and it’s basically a follow-on to the current QRA64 weak-signal mode. Q65 is optimized for weak, rapidly fading signals in the VHF bands and higher, so it’s likely to prove popular with Earth-Moon-Earth fans and those who like to do things like bounce their signals off of meteor trails. We’d think Q65 should enable airliner-bounce too. We’ll be keen to give it a try whenever it comes out.
Look, we know it’s hard to get used to writing the correct year once a new one rolls around, and that time has taken on a relative feeling in these pandemic times. But we’re pretty sure it isn’t April yet, which is the most reasonable explanation for an ad purporting the unholy coupling of a gaming PC and mass-market fried foods. We strongly suspect this is just a marketing stunt between Cooler Master and Yum! Brands, but taken at face value, the KFConsole — it’s not a gaming console, it’s at best a pre-built gaming PC — is supposed to use excess heat to keep your DoorDashed order of KFC warm while you play. In a year full of incredibly stupid things, this one is clearly in the top five.
And finally, it looks like we can all breathe a sigh of relief that our airline pilots, or at least a subset of them, aren’t seeing things. There has been a steady stream of reports from pilots flying in and out of Los Angeles lately of a person in a jetpack buzzing around. Well, someone finally captured video of the daredevil, and even though it’s shaky and unclear — as are seemingly all videos of cryptids — it sure seems to be a human-sized biped flying around in a standing position. The video description says this was shot by a flight instructor at 3,000 feet (914 meters) near Palos Verdes with Catalina Island in the background. That’s about 20 miles (32 km) from the mainland, so whatever this person is flying has amazing range. And, the pilot has incredible faith in the equipment — that’s a long way to fall in something with the same glide ratio as a brick.
Yesterday Alphabet (formerly known as Google) announced that their Wing project is launching delivery services per drone in Finland, specifically in a part of Helsinki. This comes more than a month after starting a similar pilot program in North Canberra, Australia. The drone design Wing has opted for consists not of the traditional quadcopter design, but a hybrid plane/helicopter design, with two big propellers for forward motion, along with a dozen small propellers on the top of the dual body design, presumably to give it maximum range while still allowing the craft to hover.
With a weight of 5 kg and a wingspan of about a meter, Wing’s drones are capable of lifting and carrying a payload of about 1.5 kg. This puts it into a category of drones far beyond of what hobbyists tend to fly on a regular basis, and worse, it involves Beyond Visual Line Of Sight (BVLOS for short) flying, which is frowned upon by the FAA and similar regulatory bodies. What Google/Alphabet figures that can enable them to make this kind of service a commercial reality is called Unmanned aircraft system Traffic Management (UTM).
UTM is essentially complementary to the existing air traffic control systems, allowing drones to integrate into these flows of manned airplanes without endangering either. Over the past years, it’s been part of NASA’s duty to develop the systems and infrastructure that would be required to make UTM a reality. Working together with the FAA and companies such as Amazon and Alphabet, the hope is that before long it’ll be as normal to send a drone into the skies for deliveries and more as it is today to have passenger and cargo planes with human pilots take to the skies.
Alphabet’s self-driving car offshoot, Waymo, feels that may be the case as they were recently granted a patent for vehicles that soften on impact. Sensors would identify an impending collision and adjust ‘tension members’ on the vehicle’s exterior to cushion the blow. These ‘members’ would be corrugated sections or moving panels that absorb the impact alongside the crumpling effect of the vehicle, making adjustments based on the type of obstacle the vehicle is about to strike.
Revolv, the bright red smart home hub famous for its abundance of radio modules, has finally been declared dead by its founders. After a series of acquisitions, Google’s parent company Alphabet has gained control over Revolv’s cloud service – and they are shutting it down.