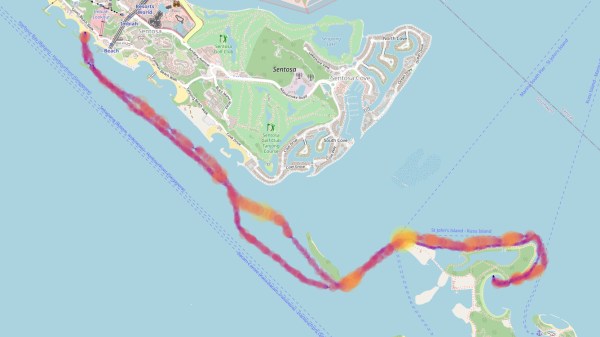
If you take to the outdoors for your exercise, rather than walking the Sisyphusian stair machine, it’s nice to grab some GPS-packed electronics to quantify your workout. [Bunnie Huang] enjoys paddling the outrigger canoe through the Singapore Strait and recently figured out how to unpack and visualize GPS data from his own Garmin watch.
By now you’ve likely heard that Garmin’s systems were down due to a ransomware attack last Thursday, July 23rd. On the one hand, it’s a minor inconvenience to not be able to see your workout visualized because of the system outage. On the other hand, the services have a lot of your personal data: dates, locations, and biometrics like heart rate. [Bunnie] looked around to see if he could unpack the data stored on his Garmin watch without pledging his privacy to computers in the sky.
Obviously this isn’t [Bunnie’s] first rodeo, but in the end you don’t need to be a 1337 haxor to pull this one off. An Open Source program called GPSBabel lets you convert proprietary data formats from a hundred or so different GPS receivers into .GPX files that are then easy to work with. From there he whipped up less than 200 lines of Python to plot the GPS data on a map and display it as a webpage. The key libraries at work here are Folium which provides the pretty browsable map data, and Matplotlib to plot the data.
These IoT devices are by all accounts amazing, listening for satellite pings to show us how far and how fast we’ve gone on web-based interfaces that are sharable, searchable, and any number of other good things ending in “able”. But the flip side is that you may not be the only person seeing the data. Two years ago Strava exposed military locations because of an opt-out policy for public data sharing of exercise trackers. Now Garmin says they don’t have any indications that data was stolen in the ransomware attack, but it’s not a stretch to think there was a potential there for such a data breach. It’s nice to see there are Open Source options for those who want access to exercise analytics and visualizations without being required to first hand over the data.