By now, you’ve surely seen the AI tools that can chat with you or draw pictures from prompts. OpenAI now has Point-E, which takes text or an image and produces a 3D model. You can find a few runnable demos online, but good luck having them not too busy to work.
We were not always impressed with the output. Asking for “3d printable starship Enterprise,” for example, produced a point cloud that looked like a pregnant Klingon battle cruiser. Like most of these tools, the trick is finding a good prompt. Simple things like “a chair” seemed to work somewhat better.
“They paved paradise and put up a parking lot.” That might be stretching things a bit, especially when the “paradise” in question is in New Jersey, but there’s a move afoot to redevelop the site of the original “Big Bang Antenna” that has some people pretty upset. Known simply as “The Horn Antenna” since it was built by Bell Labs in 1959 atop a hill in Holmdel, New Jersey, the antenna was originally designed to study long-distance microwave communications. But in 1964, Bell Labs researchers Arno Penzias and Robert Wilson accidentally discovered the microwave remnants of the Big Bang, the cosmic background radiation, using the antenna, earning it a place in scientific history. So far, the only action taken by the township committee has been to authorize a study to look into whether the site should be redeveloped. But the fact that the site is one of the highest points in Monmouth County with sweeping views of Manhattan has some people wondering what’s really on tap for the site. A petition to save the antenna currently has about 3,400 signatures, so you might want to check that out — after all, you don’t know what you’ve got ’til it’s gone.
AI knoweth everything, and as each new model breaks upon the world, it attracts a new crowd of experimenters. The new hotness is ChatGPT, and [Jonas Degrave] has turned his attention to it. By asking it to act as a Linux terminal, he discovered that he could gain access to a complete Linux virtual machine within the model’s synthetic imagination.
The AI’s first response was a prompt, so he of course first tried to list the files. Up came a list of directories, so the next step was to create a file and put some text in it. All of this resulted in a readable file, so there was some promise in this unexpected computing resource. But can it run code? Continue reading “A VM In An AI”→
The up-and-coming Wonder of the World in software and information circles , and particularly in those circles who talk about them, is AI. Give a magic machine a lot of stuff, ask it a question, and it will give you a meaningful and useful answer. It will create art, write books, compose music, and generally Change The World As We Know It. All this is genuinely impressive stuff, as anyone who has played with DALL-E will tell you. But it’s important to think about what the technology can and can’t do that’s new so as to not become caught up in the hype, and in doing that I’m immediately drawn to a previous career of mine. Continue reading “Love AI, But Don’t Love It Too Much”→
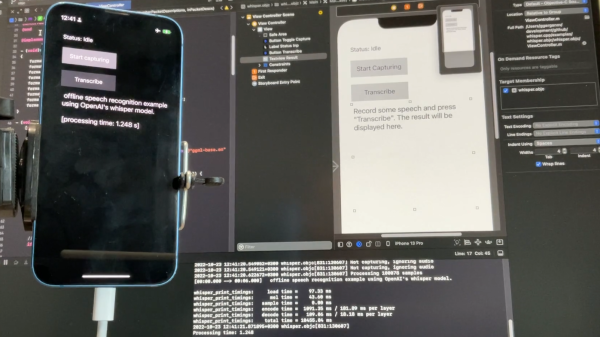
[Georgi Gerganov] recently shared a great resource for running high-quality AI-driven speech recognition in a plain C/C++ implementation on a variety of platforms. The automatic speech recognition (ASR) model is fully implemented using only two source files and requires no dependencies. As a result, the high-quality speech recognition doesn’t involve calling remote APIs, and can run locally on different devices in a fairly straightforward manner. The image above shows it running locally on an iPhone 13, but it can do more than that.
Implementing a robust speech transcription that runs locally on a variety of devices is much easier with [Georgi]’s port of OpenAI’s Whisper.[Georgi]’s work is a port of OpenAI’s Whisper model, a remarkably-robust piece of software that does a truly impressive job of turning human speech into text. Whisper is easy to set up and play with, but this port makes it easier to get the system working in other ways. Having such a lightweight implementation of the model means it can be more easily integrated over a variety of different platforms and projects.
The usual way that OpenAI’s Whisper works is to feed it an audio file, and it spits out a transcription. But [Georgi] shows off something else that might start giving hackers ideas: a simple real-time audio input example.
By using a tool to stream audio and feed it to the system every half-second, one can obtain pretty good (sort of) real-time results! This of course isn’t an ideal method, but the robustness and accuracy of Whisper is such that the results look pretty great nevertheless.
You can watch a quick demo of that in the video just under the page break. If it gives you some ideas, head over to the project’s GitHub repository and get hackin’!
[Jay Alammar] has put up an illustrated guide to how Stable Diffusion works, and the principles in it are perfectly applicable to understanding how similar systems like OpenAI’s Dall-E or Google’s Imagen work under the hood as well. These systems are probably best known for their amazing ability to turn text prompts (e.g. “paradise cosmic beach”) into a matching image. Sometimes. Well, usually, anyway.
‘System’ is an apt term, because Stable Diffusion (and similar systems) are actually made up of many separate components working together to make the magic happen. [Jay]’s illustrated guide really shines here, because it starts at a very high level with only three components (each with their own neural network) and drills down as needed to explain what’s going on at a deeper level, and how it fits into the whole.
Spot any similar shapes and contours between the image and the noise that preceded it? That’s because the image is a result of removing noise from a random visual mess, not building it up from scratch like a human artist would do.
It may surprise some to discover that the image creation part doesn’t work the way a human does. That is to say, it doesn’t begin with a blank canvas and build an image bit by bit from the ground up. It begins with a seed: a bunch of random noise. Noise gets subtracted in a series of steps that leave the result looking less like noise and more like an aesthetically pleasing and (ideally) coherent image. Combine that with the ability to guide noise removal in a way that favors conforming to a text prompt, and one has the bones of a text-to-image generator. There’s a lot more to it of course, and [Jay] goes into considerable detail for those who are interested.
You may have missed this month’s issue of Oriental Insects, in which a project by [Ildar Rakhmatulin] Heriot-Watt University in Edinburgh caught our attention. [Ildar] led a team of researchers in the development of an AI-controlled laser that neutralizes moving cockroaches at distances of up to 1.2 meters. Noting the various problems using chemical pesticides for pest control, his team sought out a non-conventional approach.
The heart of the pest controller is a Jetson Nano, which uses OpenCV and Yolo object detection to find the cockroaches and galvanometers to steer the laser beam. Three different lasers were used for testing, allowing the team to evaluate a range of wavelengths, power levels, and spot sizes. Unsurprisingly, the higher power 1.6 W laser was most efficient and quicker.
The project is on GitHub (here) and the cockroach machine learning image set is available here. But [Ildar] points out in the conclusion of the report, this is dangerous. It’s suitable for academic research, but it’s not quite ready for general use, lacking any safety features. This report is full of cockroach trivia, such as the average speed of a cockroach is 4.8 km/h, and they run much faster when being zapped. If you want to experiment with cockroaches yourself, a link is provided to a pet store that sells the German Blattela germanica that was the target of this report.
If this project sounds familiar, it is because it is an improvement of a previous project we wrote about last year which used similar techniques to zap mosquitoes.