On Friday, Reuters reported that Amazon is going to try to get into the smartphone game…again. The Fire Phone was perhaps Amazon’s biggest commercial misstep, and was only on the market for about a year before it was discontinued in the summer of 2015. But now industry sources are saying that a new phone code-named “Transformer” is in the works from the e-commerce giant.
At this point, there’s no word on how much the phone would cost or when it would hit the market. The only information Reuters was able to squeeze out of their contacts was that the device would feature AI heavily. Real shocker there — anyone with an Echo device in their kitchen could tell you that Amazon is desperate to get you talking to their gadgets, presumably so they can convince you to buy something. While a smartphone with even more AI features we didn’t ask for certainly won’t be on our Wish List, if history is any indicator, we might be able to pick these things up cheap on the second-hand market.
On the subject of AI screwing everything up, earlier this week, the Electronic Frontier Foundation reported that The New York Times had started blocking the Internet Archive’s crawlers, citing concerns over their content being scraped up by bots for training data. The EFF likens this to a newspaper asking libraries to stop storing copies of their old editions, and warns that in an era where most people get their news via the Internet, not having an archived copy of sites like The Times will put holes in the digital record. They also point out that mirroring web pages for the purposes of making them more easily searchable is a widely accepted practice (ask Google) and has been legally recognized as fair use in court.
Assuming we take the NYT’s side of the story at face value, there’s a tiny part of our cold robotic heart that feels some sympathy for them. Over the last year or so, we’ve noticed some suspicious activity that we believe to be bots siphoning up content from the blog and Hackaday.io, and it’s resulted in a few technical headaches for us. On the other hand, what’s Hackaday here for if not to share information? Surely the same could be said for any newspaper, be it the local rag or The New York Times. If a chatbot learning some new phrases from us is the cost of doing business in 2026, so be it. Can’t stop the signal.



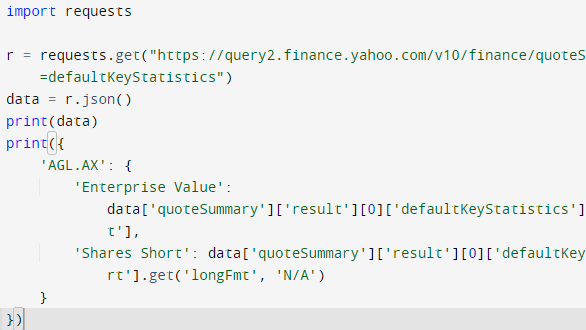
 [Doug] shows that while parsing a web page for a specific piece of data (for example, a stock price) is not difficult, there are sometimes easier and faster ways to go about it. In the case of Yahoo Finance, the web page most of us look at isn’t really the actual source of the data being displayed, it’s just a front end.
[Doug] shows that while parsing a web page for a specific piece of data (for example, a stock price) is not difficult, there are sometimes easier and faster ways to go about it. In the case of Yahoo Finance, the web page most of us look at isn’t really the actual source of the data being displayed, it’s just a front end.