Computers are known to be precise and — usually — repeatable. That’s why it is so hard to get something that seems random out of them. Yet random things are great for games, encryption, and multimedia. Who wants the same order of a playlist or slide show every time?
It is very hard to get truly random numbers, but for a lot of cases, it isn’t that important. Even better, if you programming or using a scripting language, there are lots of things that you can use to get some degree of randomness that is sufficient for many purposes. Continue reading “Linux Fu: The Linux Shuffle”→
Hackaday editors Elliot Williams and Mike Szczys kick off the first podcast of the new year. Elliot just got home from Chaos Communications Congress (36c3) with a ton of great stories, and he showed off his electric cargo carrier build while he was there. We recount some of the most interesting hacks of the past few weeks, such as 3D-printed molds for making your own paper-pulp objects, a rudimentary digital camera sensor built by hand, a tattoo-removal laser turned welder, and desktop-artillery that’s delivered in greeting-card format.
Take a look at the links below if you want to follow along, and as always tell us what you think about this episode in the comments!
Take a look at the links below if you want to follow along, and as always, tell us what you think about this episode in the comments!
A large chunk of the global economy now rests on public key cryptography. We generally agree that with long enough keys, it is infeasible to crack things encoded that way. Until such time as it isn’t, that is. Researchers published a paper a few years ago where they cracked a large number of keys in a very short amount of time. It doesn’t work on any key, as you’ll see in a bit, but here’s the interesting part: they used an undescribed algorithm to crack the codes in a very short amount of time on a single-core computer. This piqued [William Kuszmaul’s] interest and he found some follow up papers that revealed the algorithms in question. You can read his analysis, and decide for yourself how badly this compromises common algorithms.
The basis for public key cryptography is that you multiply two large prime numbers to form a product and post it publicly. Because it is computationally difficult to find prime factors of large numbers, this is reasonably secure because it is difficult to find those prime numbers that are selected randomly.
However, the random selection leads to an unusual attack. Public keys, by their very nature, are available all over the Internet. Most of them were generated with the same algorithm and random number generation isn’t actually totally random. That means some keys share prime factors and finding a common factor between two numbers isn’t nearly as difficult.
What do you do, when you need a random number in your programming? The chances are that you reach for your environment’s function to do the job, usually something like rand() or similar. This returns the required number, and you go happily on your way.
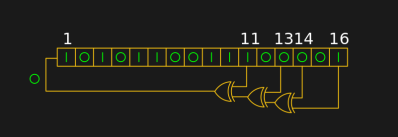
A shift register configured as a pseudo-random number generator. [by KCAuXy4p CC0 1.0]Except of course the reality isn’t quite that simple, and as many of you will know it all comes down to the level of randomness that you require. The simplest way to generate a random number in software is through a pseudo-random number generator, or PRNG. If you prefer to think in hardware terms, the most elementary PRNG is a shift register with a feedback loop from two of its cells through an XOR gate. While it provides a steady stream of bits it suffers from the fatal flaw that the stream is an endlessly repeating sequence rather than truly random. A PRNG is random enough to provide a level of chance in a computer game, but that predictability would make it entirely unsuitable to be used in cryptographic security for a financial transaction.
There is a handy way to deal with the PRNG predictability problem, and it lies in ensuring that its random number generation starts at a random point. Imagine the shift register in the previous paragraph being initialised with a random number rather than a string of zeros. This random point is referred to as the seed, and if a PRNG algorithm can be started with a seed derived from a truly unpredictable source, then its output becomes no longer predictable.
Selecting Unpredictable Seeds
Computer systems that use a PRNG will therefore often have some form of seed() function alongside their rand() function. Sometimes this will take a number as an argument allowing the user to provide their own random number, at other times they will take a random number from some source of their own. The Sinclair 8-bit home computers for example took their seed from a count of the number of TV frames since switch-on.
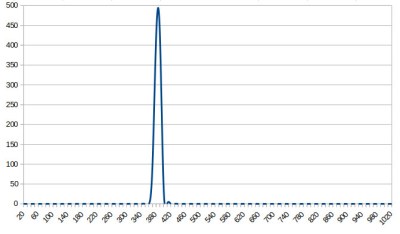
The not-very-random result of a thousand analogRead() calls.
The Arduino Uno has a random() function that returns a random number from a PRNG, and as you might expect it also has a randomSeed() function to ensure that the PRNG is seeded with something that will underpin its randomness. All well and good, you might think, but sadly the Atmel processor on which it depends has no hardware entropy source from which to derive that seed. The user is left to search for a random number of their own, and sadly as we were alerted by a Twitter conversation between @scanlime and @cybergibbons, this is the point at which matters start to go awry. The documentation for randomSeed() suggests reading the random noise on an unused pin via analogRead(), and using that figure does not return anything like the required level of entropy. A very quick test using the Arduino Graph example yields a stream of readings from a pin, and aggregating several thousand of them into a spreadsheet shows an extremely narrow distribution. Clearly a better source is called for.
Noisy Hardware or a Jittery Clock
As a slightly old-school electronic engineer, my thoughts turn straight to a piece of hardware. Source a nice and noisy germanium diode, give it a couple of op-amps to amplify and filter the noise before feeding it to that Arduino pin. Maybe you were thinking about radioactive decay and Geiger counters at that point, or even bouncing balls. Unfortunately though, even if they scratch the urge to make an interesting piece of engineering, these pieces of hardware run the risk of becoming overcomplex and perhaps a bit messy.
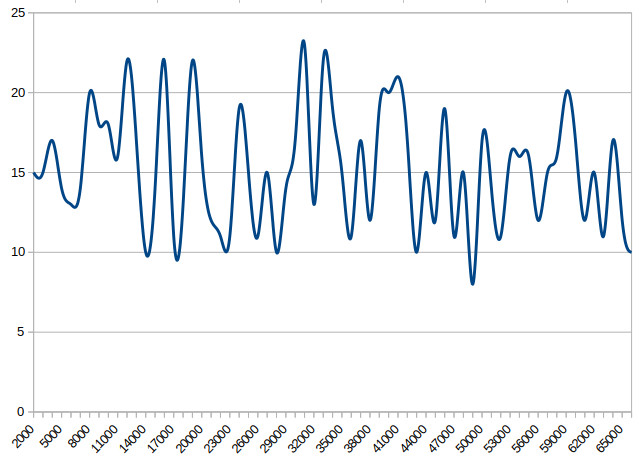
The significantly more random result of a thousand Arduino Entropy Library calls.
The best of the suggestions in the Twitter thread brings us to the Arduino Entropy Library, which uses jitter in the microcontroller clock to generate truly random numbers that can be used as seeds. Lifting code from the library’s random number example gave us a continuous stream of numbers, and taking a thousand of them for the same spreadsheet treatment shows a much more even distribution. The library performs as it should, though it should be noted that it’s not a particularly fast way to generate a random number.
So should you ever need a truly random number in your Arduino sketch rather than one that appears random enough for some purposes, you now know that you can safely disregard the documentation for a random seed and use the entropy library instead. Of course this comes at the expense of adding an extra library to the overhead of your sketch, but if space is at a premium you still have the option of some form of hardware noise generator. Meanwhile perhaps it is time for the Arduino folks to re-appraise their documentation.
One of the standout talks at the 33rd Chaos Communications Congress concerned pseudo-random-number generators (PRNGs). [Vladimir Klebanov] (right) and [Felix Dörre] (left) provided a framework for making sure that PRNGs are doing what they should. Along the way, they discovered a flaw in Libgcrypt/GNUPG, which they got fixed. Woot.
Cryptographically secure random numbers actually matter, a lot. If you’re old enough to remember the Debian OpenSSL debacle of 2008, essentially every Internet service was backdoorable due to bad random numbers. So they matter. [Vladimir] makes the case that writing good random number generators is very, very hard. Consequently, it’s very important that their output be tested very, very well.
So how can we test them? [Vladimir] warns against our first instinct, running a statistical test suite like DIEHARD. He points out (correctly) that running any algorithm through a good enough hash function will pass statistical tests, but that doesn’t mean it’s good for cryptography. Continue reading “33C3: How Can You Trust Your Random Numbers?”→
According to this post on the official V8 Javascript blog, the pseudo-random number generator (PRNG) that V8 Javascript uses in Math.random() is horribly flawed and getting replaced with something a lot better. V8 is Google’s fast Javascript engine that they developed for Chrome, and it’s used in Node.js and basically everywhere. The fact that nobody has noticed something like this for the last six years is a little bit worrisome, but it’s been caught and fixed and it’s all going to be better soon.
In this article, I’ll take you on a trip through the math of randomness, through to pseudo-randomness, and then loop back around and cover the history of the bad PRNG and its replacements. If you’ve been waiting for an excuse to get into PRNGs, you can use this bizarre fail and its fix as your excuse.
But first, some words of wisdom:
Any one who considers arithmetical methods of producing random digits is, of course, in a state of sin. For, as has been pointed out several times, there is no such thing as a random number — there are only methods to produce random numbers, and a strict arithmetic procedure of course is not such a method. John von Neumann
John von Neumann was a very smart man — that goes without saying. But in two sentences, he conveys something tremendously deep and tremendously important about random variables and their mathematical definition. Indeed, when you really understand these two sentences, you’ll understand more about randomness than most everyone you’ll meet.
Since early evening on September 5th, 2013 the US National Institute of Standards and Technology (NIST) has been publishing a 512-bit, full-entropy random number every minute of every day. What’s more, each number is cryptographically signed so that you can easily verify that it was generated by the NIST. A date stamp is included in the process, so that you can tell when the random values were created. And finally, all of the values are linked to the previous value in a chain so that you can detect if any of the past numbers in the series have been altered after the next number is published. This is quite an extensive list of features for a list of random values, and we’ll get into the rationale, methods, and uses behind this scheme in the next section, so stick around.