
Want to give an AI the ability to do stuff in Blender? The BlenderMCP addon does exactly that, connecting open-source 3D modeling software Blender to Anthropic’s Claude AI via MCP (Model Context Protocol), which means Claude can directly use Blender and its tools in a meaningful way.
MCP is a framework for allowing AI systems like LLMs (Large Language Models) to exchange information in a way that makes it easier to interface with other systems. We’ve seen LLMs tied experimentally into other software (such as with enabling more natural conversations with NPCs) but without a framework like MCP, such exchanges are bespoke and effectively stateless. MCP becomes very useful for letting LLMs use software tools and perform work that involves an iterative approach, better preserving the history and context of the task at hand.
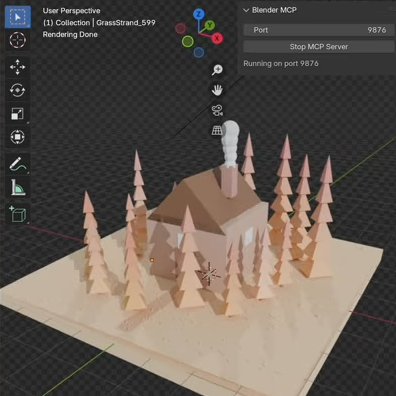
Using MCP also provides some standardization, which means that while the BlenderMCP project integrates with Claude (or alternately the Cursor AI editor) it could — with the right configuration — be pointed at a suitable locally-hosted LLM instead. It wouldn’t be as capable as the commercial offerings, but it would be entirely private.
Embedded below are three videos that really show what this tool can do. In the first, watch it create a beach scene using assets from a public 3D asset library. In the second, it creates a scene from scratch using a reference image (a ‘low-poly cabin in the woods’), followed by turning that same scene into a 3D environment on a web page, navigable in any web browser.
Back in 2022 we saw Blender connected to an image generator to texture objects, but this is considerably more capable. It’s a fascinating combination, and if you’re thinking of trying it out just make sure you’re aware it relies on allowing arbitrary Python code to be run in Blender, which is powerful but should be deployed with caution.
Continue reading “MCP Blender Addon Lets AI Take The Wheel And Wield The Tools”




![The future of healthy indoor plants, courtesy of AI. (Credit: [Liam])](https://hackaday.com/wp-content/uploads/2025/04/plantmom_test_setup_with_plant.jpg)











