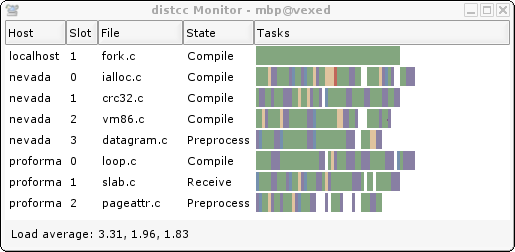
The motto of Sun Microsystems back in the day was “The Network Is The Computer” which might be kind of relevant when CPUs were slower and single-core affairs, but lately to get a faster compile, you’d simply throw more cores and memory at the problem. The thing is, most of us don’t do huge compilations all that often, we can’t remember the last time we even attempted a Linux kernel build. However if you do find yourself with a sudden need to do so, and have access to a pile of machines hooked to a network, then why not check out distcc: the fast distributed C/C++ Compiler? We’ve seen a few mentions in comments and a HaD links article referencing it, but never explicitly covered the tool. So here we go.
A great big Thank You to everyone who answered the call to participate in Folding@Home, helping to understand proteins interactions of SARS-CoV-2 virus that causes COVID-19. Some members of the FAH research team hosted an AMA (Ask Me Anything) session on Reddit to provide us with behind-the-scenes details. Unsurprisingly, the top two topics are “Why isn’t my computer doing anything?” and “What does this actually accomplish?”
The first is easier to answer. Thanks to people spreading the word — like the amazing growth of Team Hackaday — there has been a huge infusion of new participants. We could see this happening on the leader boards, but in this AMA we have numbers direct from the source. Before this month there were roughly thirty thousand regular contributors. Since then, several hundredthousands more started pitching in. This has overwhelmed their server infrastructure and resulted in what’s been termed a friendly-fire DDoS attack.
Here’s a summary of current Folding@Home situation :
* We know about the work unit shortage
* It’s happening because of an approximately 20x increase in demand
* We are working on it and hope to have a solution very soon.
* Keep your machines running, they will eventually fold on their own.
* Every time we double our server resources, the number of Donors trying to help goes up by a factor of 4, outstripping whatever we do.
Why don’t they just buy more servers?
The answer can be found on Folding@Home donation FAQ. Most of their research grants have restrictions on how that funding is spent. These restrictions typically exclude capital equipment and infrastructure spending, meaning researchers can’t “just” buy more servers. Fortunately they are optimistic this recent fame has also attracted attention from enough donors with the right resources to help. As of this writing, their backend infrastructure has grown though not yet caught up to the flood. They’re still working on it, hang tight!
Computing hardware aside, there are human limitations on both input and output sides of this distributed supercomputer. Folding@Home need field experts to put together work units to be sent out to our computers, and such expertise is also required to review and interpret our submitted results. The good news is that our contribution has sped up their iteration cycle tremendously. Results that used to take weeks or months now return in days, informing where the next set of work units should investigate.
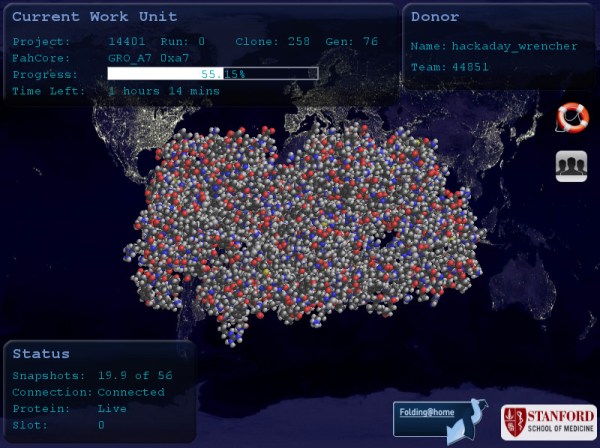
On Wednesday morning we asked the Hackaday community to donate their extra computer cycles for Coronavirus research. On Thursday morning the number of people contributing to Team Hackaday had doubled, and on Friday it had doubled again. Thank you for putting those computers to work in pursuit of drug therapies for COVID-19.
I’m writing today for two reasons, we want to keep up this trend, and also answer some of the most common questions out there. Folding@Home (FAH) is an initiative that simulates proteins associated with several diseases, searching for indicators that will help medical researchers identify treatments. These are complex problems and your efforts right now are incredibly important to finding treatments faster. FAH loads the research pipeline, generating a data set that researchers can then follow in every step of the process, from identifying which chemical compounds may be effective and how to deliver them, to testing they hypothesis and moving toward human trials.
Donate your extra computer cycles to combat COVID-19. The Folding@Home project uses computers from all over the world connected through the Internet to simulate protein folding. The point is to generate the data necessary to discover treatments that can have an impact on how this virus affects humanity. The software models protein folding in a search for pharmaceutical treatments that will weaken the virus’ ability to attack the human immune system. Think of this like mining for bitcoin but instead we’re mining for a treatment to Coronavirus.
Initially developed at Standford University and released in the year 2000, this isn’t the first time Hackaday has advocated for Folding@Home. The “Team Hackaday” folding group was started by readers back in 2005 and that team number is still active, so let’s pile on and work our way up the rankings. At the time of writing, we’re ranked 267 in the world, can we get back up to number 30 like we were in 2008? To use the comparison to bitcoin once again, this is like a mining pool except what we end up with is a show of goodwill, something I think we can all use right about now.
It was about 21 years ago that Berkley started one of the first projects that would allow you to donate idle computing time to scientific research. In particular, your computer could help crunch data from radio telescopes looking for extraterrestrial life. Want to help? You may be too late. The project is going into hibernation while they focus on analyzing data already processed.
1) Scientifically, we’re at the point of diminishing returns; basically, we’ve analyzed all the data we need for now.
2) It’s a lot of work for us to manage the distributed processing of data. We need to focus on completing the back-end analysis of the results we already have, and writing this up in a scientific journal paper.
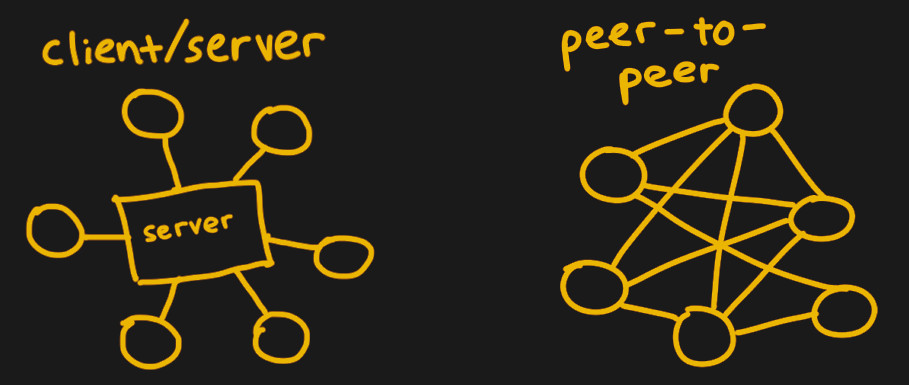
When it comes to peer-to-peer file sharing protocols, BitTorrent is probably one of the best known. It requires a client implementing the program and a tracker to list files available to transfer and to find peer users to transfer those files. Developed in 2001, BitTorrent has since acquired more than a quarter billion users according to some estimates.
While most users choose to use existing clients, [Jesse Li] wanted to build one from scratch in Go, a programming language commonly used for its built-in concurrency features and simplicity compared to C.
Client-server versus peer-to-peer architecture
The first step for a client is finding peers to download files from. Trackers, web servers running over HTTP, serve as centralized locations for introducing peers to one another. Due to the centralization, the servers are at risk of being discovered and shut down if they facilitate illegal content exchange. Thus, making peer discovery a distributed process is a necessity for preventing trackers from following in the footsteps of the now-defunct TorrentSpy, Popcorn Time, and KickassTorrents.
The client starts off by reading a .torrent file, which describes the contents of the desired file and how to connect to a tracker. The information in the file includes the URL of the tracker, the creation time, and SHA-1 hashes of each piece, or a chunk of the file. One file can be made up of thousands of pieces – the client will need to download the pieces from peers, check the hashes against the torrent file, and finally assemble the pieces together to finally retrieve the file. For the implementation, [Jesse] chose to keep the structures in the Go program reasonably flat, separating application structs from serialization structs. Pieces are also separated into slices of hashes to more easily access individual hashes.
The bitfield explained as a coffee shop loyalty card.
Next, a GET request to an `announce` URL in the torrent file announces the presence of the client to peers and retrieves a response from the tracker with the list of peers. To start downloading pieces, the client starts a TCP connection with a peer, completes a two-way BitTorrent handshake, and exchanges messages to download pieces.
One interesting data structure exchanged in the messages is a bitfield, which acts as a byte array that checks which pieces a peer has. Bits are flipped when their respective piece’s status changes, acting somewhat like a loyalty card with stamps.
While talking to one peer may be straightforward, managing the concurrency of talking to multiple peers at once requires solving a classically Hard problem. [Jesse] implements this in Go by using channels as thread-safe queues, setting up two channels to assign work and collect downloaded pieces. Requests are later pipelined to increase throughput since network round-trips are expensive and sending blocks individually inefficient.
The full implementation is available on GitHub, and is easy enough to use as an alternative client or as a walkthrough if you’d prefer to build your own.
Distributed computing is an excellent idea. We have a huge network of computers, many of them always on, why not take advantage of that when the user isn’t? The application that probably comes to mind is Folding@home, which lets you donate your unused computer time to help crunch the numbers for disease research. Everyone wins!
But what if your CPU cycles are being used for profit without your knowledge? Over the weekend this turned out to be the case with Showtime on-demand sites which mined Monero coins while the users was pacified by video playback. The video is a sweet treat while the cost of your electric bill is nudged up ever so slightly.
It’s an interesting hack as even if the user notices the CPU maxing out they’ll likely dismiss it as the horsepower necessary to decode the HD video stream. In this case, both Showtime and the web analytics company whose Javascript contained the mining software denied responsibility. But earlier this month Pirate Bay was found to be voluntarily testing out in-browser mining as a way to make up for dwindling ad revenue.
This is a clever tactic, but comes perilously close to being malicious when done without the user’s permission or knowledge. We wonder if those ubiquitous warnings about cookie usage will at times include notifications about currency mining on the side? Have you seen or tried out any of this Javascript mining? Let us know in the comments below.