Launch a single static binary executable, send someone a QR code or URL (or failing that, text a numerical code or shout it across a room), and they’ll get an encrypted terminal in their browser. No VPN, no port forwarding, no firewall modifications, and no account setup required. It’s BitBang by [Rich LeGrand], and there is a lot to go through in this one.
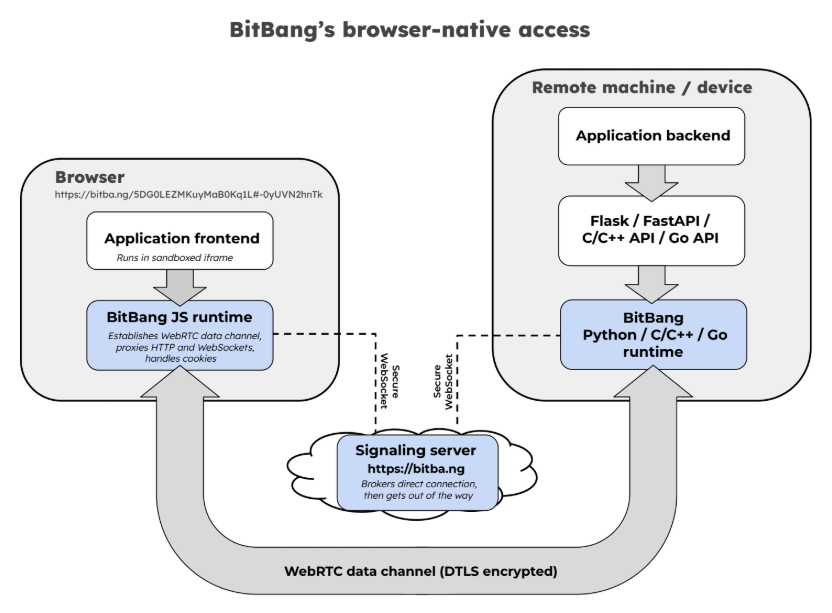
The best part? It’s not actually limited to just firing off a terminal. It’s a whole open framework for establishing an encrypted peer-to-peer connection between two systems over WebRTC without needing either a trusted central authority, or any special network configuration.
Opening a remote terminal, transferring files, or accessing web apps on a remote machine’s network is done with bitbang-cli, an implementation of BitBang focused on providing simple, zero-config remote access.
Before we go on, we want to mention that BitBang does require a lightweight, trustless signaling server only to broker the initial connection, but more on that in a moment.
On the machine to be shared, one first downloads the binary. Easiest way to do that is to go to bitba.ng and download manually, or copy and paste the one-line installer to auto-detect one’s system, download the correct release, and verify the checksum.
After the binary is downloaded, simply run it in a terminal and receive a QR code to scan, a URL to copy & paste, or a numerical code if those are inconvenient. One the remote side, one accesses the signaling server and the connection is made — one gets a terminal on the target machine open in the browser tab, with added options for file sharing and accessing web applications on the target network.
The signaling server isn’t involved in authentication or encryption, and couldn’t see private data between the two ends even if it wanted to. Prefer not to use someone else’s regardless? Run your own local instance with bitbang-server.
Originally developed as an easy way to securely make telepresence robots reachable over the Internet with nothing more than a QR code, today it’s a whole framework.
It includes not just the remote-access tool mentioned above, but also a BitBang Octoprint plugin for cloud-free remote access to 3D printers, and bitbang-python is a library for turning local Python web applications into a URL that can be opened from anywhere.
We’re sure some of you are getting more than a few ideas from this. If it lets you bring a project over the finish line, let us know on our tips line.