Let’s be honest, no one likes to see their program crash. It’s a clear sign that something is wrong with our code, and that’s a truth we don’t like to see. We try our best to avoid such a situation, and we’ve seen how compiler warnings and other static code analysis tools can help us to detect and prevent possible flaws in our code, which could otherwise lead to its demise. But what if I told you that crashing your program is actually a great way to improve its overall quality? Now, this obviously sounds a bit counterintuitive, after all we are talking about preventing our code from misbehaving, so why would we want to purposely break it?
Wandering around in an environment of ones and zeroes makes it easy to forget that reality is usually a lot less black and white. Yes, a program crash is bad — it hurts the ego, makes us look bad, and most of all, it is simply annoying. But is it really the worst that could happen? What if, say, some bad pointer handling doesn’t cause an instant segmentation fault, but instead happily introduces some garbage data to the system, widely opening the gates to virtually any outcome imaginable, from minor glitches to severe security vulnerabilities. Is this really a better option? And it doesn’t have to be pointers, or anything of C’s shortcomings in particular, we can end up with invalid data and unforeseen scenarios in virtually any language.
It doesn’t matter how often we hear that every piece of software is too complex to ever fully understand it, or how everything that can go wrong will go wrong. We are fully aware of all the wisdom and cliches, and completely ignore them or weasel our way out of it every time we put a /* this should never happen */ comment in our code.
So today, we are going to look into our options to deal with such unanticipated situations, how we can utilize a deliberate crash to improve our code in the future, and why the average error message is mostly useless.
Continue reading “Crash Your Code – Lessons Learned From Debugging Things That Should Never Happen™” →

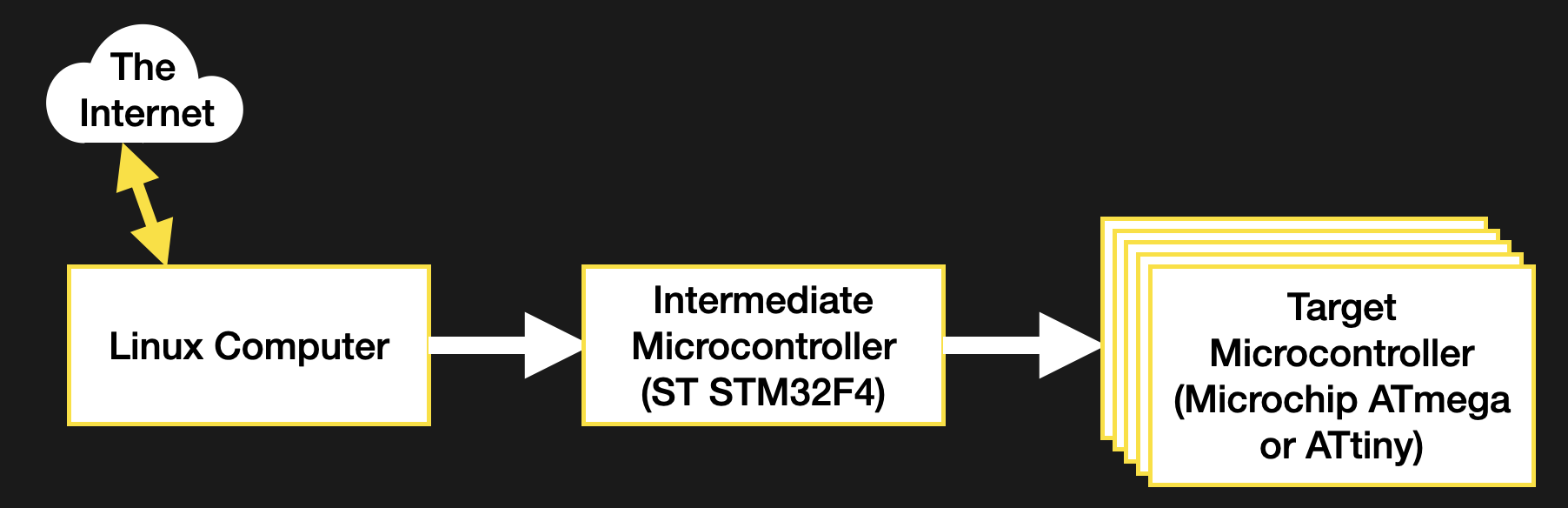



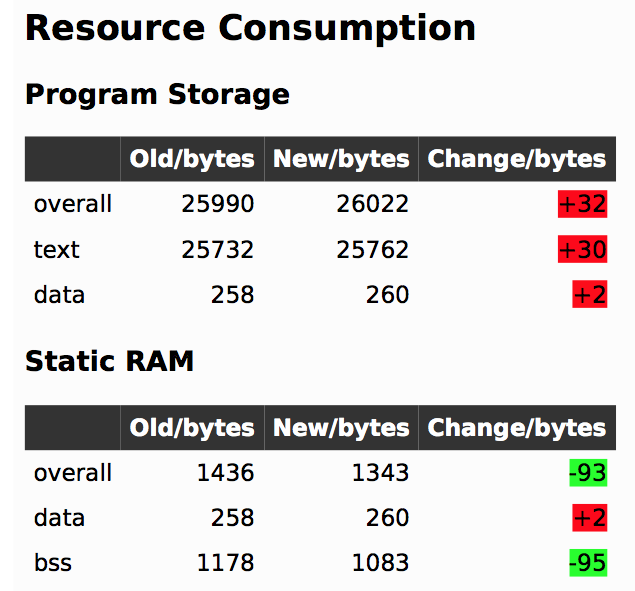 In firmware-land, where flash space can be limited, it’s nice to keep a handle on code size. This can be done a number of ways. Manual inspection of .map files (colloquially “mapfiles”) is the easiest place to start but not conducive to automatic tracking over time. Mapfiles are generated by the linker and track the compiled sizes of object files generated during build, as well as the flash and RAM layouts of the final output files.
In firmware-land, where flash space can be limited, it’s nice to keep a handle on code size. This can be done a number of ways. Manual inspection of .map files (colloquially “mapfiles”) is the easiest place to start but not conducive to automatic tracking over time. Mapfiles are generated by the linker and track the compiled sizes of object files generated during build, as well as the flash and RAM layouts of the final output files. 










