With the rise in voice-driven virtual assistants over the years, the sight of people talking to various electrical devices in public and in private has become rather commonplace. While such voice-driven interfaces are decidedly useful for a range of situations, they also come with complications. One of these are the trigger phrases or wake words that voice assistants listen to when in standby. Much like in Star Trek, where uttering ‘Computer’ would get the computer’s attention, so do we have our ‘Siri’, ‘Cortana’ and a range of custom trigger phrases that enable the voice interface.
Unlike in Star Trek, however, our virtual assistants do not know when we really desire to interact. Unable to distinguish context, they’ll happily respond to someone on TV mentioning their trigger phrase. This possibly followed by a ludicrous purchase order or other mischief. The realization here is the complexity of voice-based interfaces, while still lacking any sense of self-awareness or intelligence.
Another issue is that the process of voice recognition itself is very resource-intensive, which limits the amount of processing that can be performed on the local device. This usually leads to the voice assistants like Siri, Alexa, Cortana and others processing recorded voices in a data center, with obvious privacy implications.
[Jay Alammar] has put up an illustrated guide to how Stable Diffusion works, and the principles in it are perfectly applicable to understanding how similar systems like OpenAI’s Dall-E or Google’s Imagen work under the hood as well. These systems are probably best known for their amazing ability to turn text prompts (e.g. “paradise cosmic beach”) into a matching image. Sometimes. Well, usually, anyway.
‘System’ is an apt term, because Stable Diffusion (and similar systems) are actually made up of many separate components working together to make the magic happen. [Jay]’s illustrated guide really shines here, because it starts at a very high level with only three components (each with their own neural network) and drills down as needed to explain what’s going on at a deeper level, and how it fits into the whole.
Spot any similar shapes and contours between the image and the noise that preceded it? That’s because the image is a result of removing noise from a random visual mess, not building it up from scratch like a human artist would do.
It may surprise some to discover that the image creation part doesn’t work the way a human does. That is to say, it doesn’t begin with a blank canvas and build an image bit by bit from the ground up. It begins with a seed: a bunch of random noise. Noise gets subtracted in a series of steps that leave the result looking less like noise and more like an aesthetically pleasing and (ideally) coherent image. Combine that with the ability to guide noise removal in a way that favors conforming to a text prompt, and one has the bones of a text-to-image generator. There’s a lot more to it of course, and [Jay] goes into considerable detail for those who are interested.
We love the intersection between art and technology, and a video made by an AI (Stable Diffusion) imagining a journey through time (Nitter) is a lovely example. The project is relatively straightforward, but as with most art projects, there were endless hours of [Xander Steenbrugge] tweaking and playing with different parts of the process until it was just how he liked it. He mentions trying thousands of different prompts and seeds — an example of one of the prompts is “a small tribal village with huts.” In the video, each prompt got 72 frames, slowly increasing in strength and then decreasing as the following prompt came along.
There are other AI videos on YouTube, often putting the lyrics of a song into AI-generated form. But if you’ve worked with AI systems, you’ll notice that the background stays remarkably stable in [Xander]’s video as it goes through dozens of feedback loops. This is difficult to do as you want to change the image’s content without changing the look. So he had to write a decent amount of code to try and maintain visual temporal cohesion over time. Hopefully, we’ll see an open-source version of some of his improvements, as he mentioned on Twitter.
In the meantime, we get to sit back and enjoy something beautiful. If you still aren’t convinced that Stable Diffusion isn’t a big deal, perhaps we can do a little more to persuade your viewpoint.
As anyone who has taken care of chickens or other poultry before will tell you, it can be backbreaking work. So why not build a robot to do all the hard work for us? That’s precisely what [Aktar Kutluhan] demonstrated with an AI-powered IoT system that automatically feeds chicks and monitors unhatched eggs.
Make no mistake, hens are adorable, feathered creatures, but they can be quite finicky. An egg’s weight, size, and frequency can determine the overall health of a hen, and they can stop laying eggs altogether if something as simple as their feeding schedule is too sporadic. This is precisely what inspired [Aktar] to create a system that can feed hens at a consistent time every day while keeping track of the eggs laid to ensure the coop is happy and healthy.
What’s so impressive about this build isn’t just the clever automation that scratches off a daily chore, it’s built completely with IoT devices, including the AI. The setup uses Edge Impulse as an object detection model on an OPenMV Cam H7 microcontroller to recognize eggs in the coop. From there, an WizFi360-EVB-Pico board was attached so data could be sent over WiFi, with a DHT22 thrown in to monitor and record the overall temperature of the coop.
This is already an amazing setup, but when it comes to IoT devices, the sky’s the limit. You could control heat lamps in larger coops, automatically refill a water bowl if the hens’ water is low, or even build a hands-off incubator. We’re only just beginning to see the clever ways with which AI can help monitor our pet’s health. Just look at how another hacker used AI to monitor cat poop to make sure their furry friend wasn’t eating plastic. Thanks to [Aktar Kutluhan] for showing us more ways we can use AI to help our pets!
What do SQL injection attacks have in common with the nuances of GPT-3 prompting? More than one might think, it turns out.
Many security exploits hinge on getting user-supplied data incorrectly treated as instruction. With that in mind, read on to see [Simon Willison] explain how GPT-3 — a natural-language AI — can be made to act incorrectly via what he’s calling prompt injection attacks.
This all started with a fascinating tweet from [Riley Goodside] demonstrating the ability to exploit GPT-3 prompts with malicious instructions that order the model to behave differently than one would expect.
This modern era of GPU-accelerated AI applications have their benefits. Pulling useful information out of mountains of raw data, alerting users to driving hazards, or just keeping an eye on bee populations are all helpful. Lately there has been a rise in attempts at producing (or should that be curating?) works of art out of carefully sculpted inputs.
One such AI art project is midjourney, which can be played with via a Discord integration bot. That bot takes some textual input, then “dreams” with it, producing sometime uncanny, often downright disturbing images.
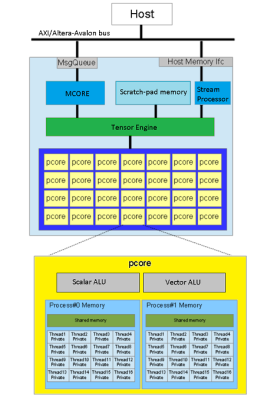
[Vuong Nguyen] clearly knows his way around artificial intelligence accelerator hardware, creating ztachip: an open source implementation of an accelerator platform for AI and traditional image processing workloads. Ztachip (pronounced “zeta-chip”) contains an array of custom processors, and is not tied to one particular architecture. Ztachip implements a new tensor programming paradigm that [Vuong] has created, which can accelerate TensorFlow tasks, but is not limited to that. In fact it can process TensorFlow in parallel with non-AI tasks, as the video below shows.
A RISC-V core, based on the VexRiscV design, is used as the host processor handling the distribution of the application. VexRiscV itself is quite interesting. Written in SpinalHDL (a Scala variant), it’s super configurable, producing a Verilog core, ready to drop into the design.
A Digilent Arty-A7, Arducam and a VGA PMOD is all you need
From a hardware design perspective the RISC-V core hooks up to an AXI crossbar, with all the AXI-lite busses muxed as is usual for the AMBA AXI ecosystem. The Ztachip core as well as a DDR3 controller are also connected, together with a camera interface and VGA video.
Other than providing an FPGA-specific DDR3 controller and AXI crossbar IP, the rest of the design is generic RTL. This is good news. The demo below deploys onto an Artix-7 based Digilent (Arty-A7) with a VGA PMOD module, but little else needed. Pre-build Xilinx IP is provided, but targeting a different FPGA shouldn’t be a huge task for the experienced FPGA ninja.
Ztachip top level architecture
The magic happens in the Ztachip core, which is mostly an array of Pcores. Each Pcore has both vector and scalar processing capability, making it super flexible. The Tensor Engine (internally this is the ‘dataplane processor’) is in charge here, sending instructions from the RISC-V core into the Pcore array together with image data, as well as streaming video data out. That camera is only a 0.3 MP Arducam, and the video is VGA resolution, but give it a bigger FPGA and those limits could be raised.
This domain-specific approach uses a highly modified C-like language (with a custom compiler) to describe the application that is to be distributed across the accelerator array. We couldn’t find any documentation on this, but there are a few example algorithms.
The demo video shows a real-time mix of four algorithms running in parallel; one object classification (Google’s Tensorflow mobilenet-ssd, a pre-trained AI model) canny edge detection, a Harris corner detection, and Optical flow which gives it a predator-like motion vision.
[Vuong] reckons, efficiency wise it is 5.5x more computationally efficient than a Jetson Nano and 37x more than Google’s TPU edge. These are bold claims, to say the least, but who are we to argue with a clearly incredibly talented engineer?