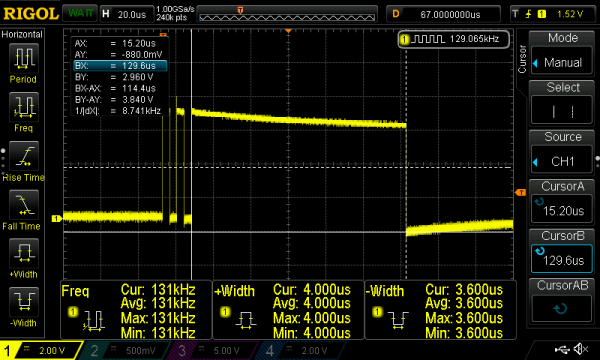
We get it, press releases are full of hyperbole. Cerebras recently announced they’ve built the largest chip ever. The chip has 400,000 cores and contains 1.2 trillion transistors on a die over 46,000 square mm in area. That’s roughly the same as a square about 8.5 inches on each side. But honestly, the WSE — Wafer Scale Engine — is just most of a wafer not cut up. Typically a wafer will have lots of copies of a device on it and it gets split into pieces.
According to the company, the WSE is 56 times larger than the largest GPU on the market. The chip boasts 18 gigabytes of storage spread around the massive die. The problem isn’t making such a beast — although a normal wafer is allowed to have a certain number of bad spots. The real problems come through things such as interconnections and thermal management.
Even though machine learning AKA ‘deep learning’ / ‘artificial intelligence’ has been around for several decades now, it’s only recently that computing power has become fast enough to do anything useful with the science.
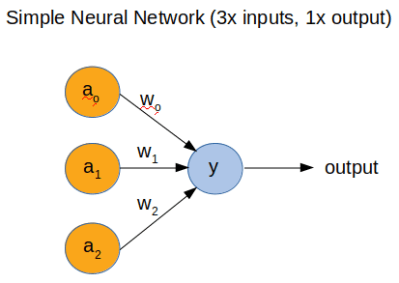
However, to fully understand how a neural network (NN) works, [Dimitris Tassopoulos] has stripped the concept down to pretty much the simplest example possible – a 3 input, 1 output network – and run inference on a number of MCUs, including the humble Arduino Uno. Miraculously, the Uno processed the network in an impressively fast prediction time of 114.4 μsec!
Whilst we did not test the code on an MCU, we just happened to have Jupyter Notebook installed so ran the same code on a Raspberry Pi directly from [Dimitris’s] bitbucket repo.
He explains in the project pages that now that the hype about AI has died down a bit that it’s the right time for engineers to get into the nitty-gritty of the theory and start using some of the ‘tools’ such as Keras, which have now matured into something fairly useful.
In part 2 of the project, we get to see the guts of a more complicated NN with 3-inputs, a hidden layer with 32 nodes and 1-output, which runs on an Uno at a much slower speed of 5600 μsec.
This exploration of ML in the embedded world is NOT ‘high level’ research stuff that tends to be inaccessible and hard to understand. We have covered Machine Learning On Tiny Platforms Like Raspberry Pi And Arduino before, but not with such an easy and thoroughly practical example.
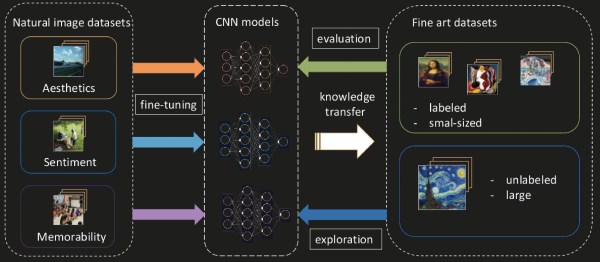
In 2019, using AI to evaluate artwork is finally more productive than foolish. We all hope that someday soon our Roomba will judge our living habits and give unsolicited advice on how we could spruce things up with a few pictures and some natural light. There is already an extensive amount of Deep Learning dedicated to photo recognition but a team in Croatia is adapting them for use on fine art. It makes sense that everything is geared toward cameras since most of us have a vast photographic portfolio but fine art takes longer to render. Even so, the collection on Wikiart.org is vast and already a hotbed for computer classification work, so they set to work there.
As they modify existing convolutional neural networks, they check themselves by comparing results with human ratings to keep what works and discard what flops. Fortunately, fine art has a lot of existing studies and commentary, whereas the majority of photographs in the public domain have nothing more than a file name and maybe some EXIF data. The difference here is that photograph-parsing AI can say, “That is a STOP sign,” while the fine art AI can say, “That is a memorable painting of a sign.” Continue reading “AI And Art Appreciation”→
The current wave of excitement around machine learning kicked off when graphics processors were repurposed to make training deep neural networks practical. Nvidia found themselves the engine of a new revolution and seized their opportunity to help push frontiers of research. Their research lab in Seattle will focus on one such field: making robots smart enough to work alongside humans in an IKEA kitchen.
Today’s robots are mostly industrial machines that require workspaces designed for robots. They run day and night, performing repetitive tasks, usually inside cages to keep squishy humans out of harm’s way. Robots will need to be a lot smarter about their surroundings before we could safely dismantle those cages. While there are some industrial robots making a start in this arena, they have a hard time justifying their price premium. (Example: financial difficulty of Rethink Robotics, who made the Baxter and Sawyer robots.)
So there’s a lot of room for improvement in this field, and this evolution will need a training environment offering tasks of varying difficulty levels for robots. Anywhere from the rigorous structured environment where robots work well today, to a dynamic unstructured environment where robots are hopelessly lost. Lab lead Dr. Dieter Fox explained how a kitchen is ideal. A meticulously cleaned and organized kitchen is very similar to an industrial setting. From there, we can gradually make a kitchen more challenging for a robot. For example: today’s robots can easily pick up a can with its rigid regular shape, but what about a half-full bag of flour? And from there, learn to pick up a piece of fresh fruit without bruising it. These tasks share challenges with many other tasks outside of a kitchen.
This isn’t about building a must-have home cooking robot, it’s about working through the range of challenges shared with common kitchen tasks. The lab has a lot of neat hardware, but its success will be measured by the software, and like all research, published results should be reproducible by other labs. You don’t have a high-end robotics lab in your house, but you do have a kitchen. That’s why it’s not just any kitchen, but an IKEA kitchen, to take advantage of the fact they are standardized, affordable, and available around the world for other robot researchers to benchmark against.
Most of us can experiment in a kitchen, IKEA or not. We have access to all the other tools we need: affordable AI hardware from Google, from Beaglebone, and from Nvidia. And we certainly have no shortage of robot arms and manipulators on these pages, ranging from a small laser-cut MeArm to our 2018 Hackaday Prize winner Dexter.
Convolutional Neural Networks or CNNs are a class of Deep learning networks that reduces the number of computations to be performed by creating hierarchical patterns from simpler and smaller networks. They are becoming the norm for image recognition applications and are being used in the field. In this new paper, the addition of color patches is seen to confuse the image detector YoLo(v2) by adding noise that disrupts the calculations of the CNN. The patch is not random and can be identified using the process defined in the publication.
This attack can be implemented by printing the disruptive pattern on a t-shirt making them invisible to surveillance system detection. You can read the paper[PDF] that outlines the generation of the adversarial patch. Image recognition camouflage that works on Google’s Inception has been documented in the past and we hope to see more such hacks in the future. Its a new world out there where you hacking is colorful as ever.
One of the things that makes us human is our ability to communicate. However, a stroke or other medical impairment can take that ability away without warning. Although Stephen Hawking managed to do great things with a computer-aided voice, it took a lot of patience and technology to get there. Composing an e-mail or an utterance for a speech synthesizer using a tongue stick or by blinking can be quite frustrating since most people can only manage about ten words a minute. Conventional speech averages about 150 words per minute. However, scientists recently reported in the journal Nature that they have successfully decoded brain signals into speech directly, which could open up an entirely new world for people who need assistance communicating.
The tech is still only lab-ready, but they claim to be able to produce mostly intelligible sentences using the technique. Previous efforts have only managed to produce single syllables, not entire sentences.
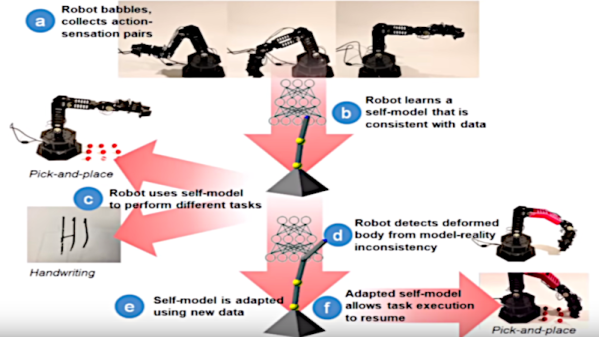
If you ever tried to program a robotic arm or almost any robotic mechanism that has more than 3 degrees of freedom, you know that a big part of the programming goes to the programming of the movements themselves. What if you built a robot, regardless of how you connect the motors and joints and, with no knowledge of itself, the robot becomes aware of the way it is physically built?
That is what Columbia Engineering researchers have made by creating a robot arm that learns how it is connected, with zero prior knowledge of physics, geometry, or motor dynamics. At first, the robot has no idea what its shape is, how its motors work and how they affect its movement. After one day of trying out its own outputs in a pretty much random fashion and getting feedback of its actions, the robot creates an accurate internal self-simulation of itself using deep-learning techniques.
The robotic arm used in this study by Lipson and his PhD student Robert Kwiatkowski is a four-degree-of-freedom articulated robotic arm. The first self-models were inaccurate as the robot did not know how its joints were connected. After about 35 hours of training, the self-model became consistent with the physical robot to within four centimeters. The self-model then performed a pick-and-place task that enabled the robot to recalibrate its original position between each step along the trajectory based entirely on the internal self-model.
To test whether the self-model could detect damage to itself, the researchers 3D-printed a deformed part to simulate damage and the robot was able to detect the change and re-train its self-model. The new self-model enabled the robot to resume its pick-and-place tasks with little loss of performance.
Since the internal representation is not static, not only this helps the robot to improve its performance over time but also allows it to adapt to damage and changes in its own structure. This could help robots to continue to function more reliably when there its part start to wear off or, for example, when replacement parts are not exactly the same format or shape.
Of course, it will be long before this arm can get a precision anywhere near Dexter, the 2018 Hackaday Prize winner, but it is still pretty cool to see the video of this research: