![[Piers] explains his code](https://hackaday.com/wp-content/uploads/2025/11/One-ROM-PIO-banner.jpg?w=600&h=450)
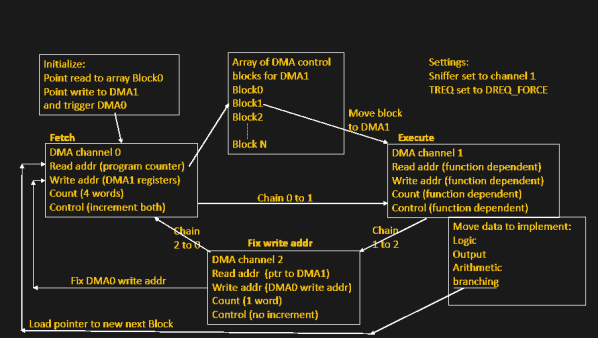
Here’s a fun rabbit hole to run down if you don’t already have the RP2040/RP2350 PIO feather in your cap: how to serve data without CPU intervention using PIO and DMA on the RP2350.
If you don’t know much about the RP2040 or RP2350 here’s the basic run down: the original Raspberry Pi Pico was released in 2021 with the RP2040 at its heart, with the RP2350 making its debut in 2024 with the Pico 2. Both microcontrollers include a feature known as Programmed I/O (PIO), which lets you configure tiny state machines and other facilities (shift registers, scratch registers, FIFO buffers, etc) to process simple I/O logic, freeing up the CPU to do other tasks.
The bottom line is that you can write very simple programs to do very fast and efficient I/O and these programs can run separately to the other code running on your micro. In the video below, [piers] explains how it works and how he’s used it in his One ROM project.
This is the latest installment from [piers rocks] whose One ROM project we’ve been tracking since July this year when we first heard about it. Since then we’ve been watching this project grow up and we were there when it was only implemented on the STM32F4, when it was renamed to One ROM, and when it got its USB stack. Along the way [piers rocks] was on FLOSS Weekly Episode 850: One ROM To Rule Them All too.
Have you seen PIO being put to good use in other projects? Let us know in the comments, or on the tips line!
Continue reading “A Deep Dive Into Using PIO And DMA On The RP2350”