The more glass we punch with our fingertips, the more we miss fun physical interfaces like the rotary phone. Sure, they took forever to dial, and you did not want to be one of those kids stuck with one during the transition to DTMF, especially if you were trying to be the 9th caller to a radio station, but the solidly electromechanical experience of it all was just cool, okay? The sound and the heft made them seem so adult.
[Tal O] gets it. He’s all but finished bringing this old girl into the 21st century without giving anything away on her surface. Inside are some things you’d expect, like a SIM800 GSM module for the telephony part, and an ESP32 to count the pulses from the dialer and communicate between it and the GSM module. But it also has a few things we haven’t seen before. The entire journey is outlined in a five-part video series, and we’ve got part one dialed in for you after the break.
Although [Tal] got the ringer working to prove it could be done, he didn’t want to have a separate 12V circuit just to run the bells. Also, the bells and their electromagnets take up a lot of space, so he compromised with an mp3 of a rotary ringer. [Tal] also wanted a way to have dialed-number feedback without cutting up the phone to add a screen, so he found a text-to-speech library and made the phone speak each number aloud as soon as it’s dialed. It uses the same internal speaker as the ringer, but we think it would be neat if the feedback came through the handset speaker.
If [Tal] is looking for another modern convenience to add to this phone, how about speed dial?
What’s worse than unleashing a monster on the internet? Allowing the internet to control the monster! But that’s just what [8BitsAndAByte] did, created a monster that anyone on the internet can control. Luckily for us, this monster only talks.
This is a very simple project and most of the parts are off the shelf. Hardware wise the monster’s body is made out of a plastic flowerpot; its mouth is a bit of wood that covers the top of the flowerpot; its eyes, two halves of a plastic sphere painted white with some felt for irises. And then whole thing is covered in some blue fake fur.
Electronics wise, a Raspberry Pi is running the show and handling the text-to-speech is an AIY Voice Hat. A servo fits inside the flowerpot to open and close the monster’s mouth. On the software end of things, a bit of Python has been written that waits for a bit of text, sends it off to the Voice Hat’s text-to-speech module and moves the servo to open and close the mouth. The scary part, connecting the monster to the internet, is done with remo.tv, which is some open-source code hosted on GitHub specifically for allowing control of robots over the internet.
This is a neat little project which is simple enough that kids could build one themselves. The instructions and the python script are up on the Instructables page, and you can see the monster in action at its page on remo.tv. Perhaps [8BitsAndAByte] could add a couple of these internet controlled robot arms to the monster to create a monster that could create some real havoc!
[pepelepoisson]’s Miroir Magique (“Magic Mirror”) is an interesting take on the smart mirror concept; it’s intended to be a playful, interactive learning tool for kids who are at an age where language and interactivity are deeply interesting to them, but whose ceaseless demands for examples of spelling and writing can be equally exhausting. Inspiration came from his own five-year-old, who can neither read nor write but nevertheless has a bottomless fascination with the writing and spelling of words, phrases, and numbers.
Magic Mirror is listening
The magic is all in the simple interface. Magic Mirror waits for activation (a simple pass of the hand over a sensor) then shows that it is listening. Anything it hears, it then displays on the screen and reads back to the user. From an application perspective it’s fairly simple, but what’s interesting is the use of speech-to-text and text-to-speech functions not as a means to an end, but as an end in themselves. A mirror in more ways than one, it listens and repeats back, while writing out what it hears at the same time. For its intended audience of curious children fascinated by the written and spoken aspects of language, it’s part interactive toy and part learning tool.
Like most smart mirror projects the technological elements are all hidden; the screen is behind a one-way mirror, speakers are out of sight, and the only inputs are a gesture sensor and a microphone embedded into the frame. Thus equipped, the mirror can tirelessly humor even the most demanding of curious children.
[pepelepoisson] explains some of the technical aspects on the project page (English translation link here) and all the code and build details are available (in French) on the project’s GitHub repository. Embedded below is a demonstration of the Magic Mirror, first in French then switching to English.
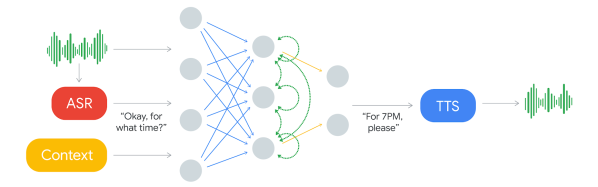
First Google gradually improved its WaveNet text-to-speech neural network to the point where it sounds almost perfectly human. Then they introduced Smart Reply which suggests possible replies to your emails. So it’s no surprise that they’ve announced an enhancement for Google Assistant called Duplex which can have phone conversations for you.
What is surprising is how well it works, as you can hear below. The first is Duplex calling to book an appointment at a hair salon, and the second is it making reservation’s with a restaurant.
Note that this reverses the roles when talking to a computer on the phone. The computer is the customer who calls the business, and the human is on the business side. The goal of the computer is to book a hair appointment or reserve a table at a restaurant. The computer has to know how to carry out a conversation with the human without the human knowing that they’re talking to a computer. It’s for communicating with all those businesses which don’t have online booking systems but instead use human operators on the phone.
Not knowing that they’re talking to a computer, the human will therefore speak as it would with another human, with all the pauses, “hmm”s and “ah”s, speed, leaving words out, and even changing the context in mid-sentence. There’s also the problem of multiple meanings for a phrase. The “four” in “Ok for four” can mean 4 pm or four people.
The component which decides what to say is a recurrent neural network (RNN) trained on many anonymized phone calls. The input is: the audio, the output from Google’s automatic speech recognition (ASR) software, and context such as the conversation’s history and the parameters of the conversation (e.g. book places at a restaurant, for how many, when), and more.
Producing the speech is done using Google’s text-to-speech technologies, Wavenet and Tacotron. “Hmm”s and “ah”s are inserted for a more natural sound. Timing is also taken into account. “Hello?” gets an immediate response. But they introduce latency when responding to more complex questions since replying too soon would sound unnatural.
There are limitations though. If it decides it can’t complete a task then it hands the conversation over to a human operator. Also, Duplex can’t handle a general conversation. Instead, multiple instances are trained on different domains. So this isn’t the singularity which we’ve talked about before. But if you’re tired of talking to computers at businesses, maybe this will provide a little payback by having the computer talk to the business instead.
On a more serious note, would you want to know if the person you were speaking to was in fact a computer? Perhaps Google should preface each conversation with “Hi! This is Google Assistant calling.” And even knowing that, would you want to have a human conversation with a computer, knowing that it’s “um”s were artificial? This may save time for the person whom the call is on behalf of, but the person being called may wish the computer would be a little more computer-like and speak more efficiently. Let us know your thoughts in the comments below. Or just check out the following Google I/O ’18 keynote presentation video where all this was announced.
We can almost count on our eyesight to fail with age, maybe even past the point of correction. It’s a pretty big flaw if you ask us. So, how can a person with aging eyes hope to continue reading the printed word?
There are plenty of commercial document readers available that convert text to speech, but they’re expensive. Most require a smart phone and/or an internet connection. That might not be as big of an issue for future generations of failing eyes, but we’re not there yet. In the meantime, we have small, cheap computers and plenty of open source software to turn them into document readers.
[rgrokett] built a RaspPi text reader to help an aging parent maintain their independence. In the process, he made a good soup-to-nuts guide to building one. It couldn’t be easier to use—just place the document under the camera and push the button. A Python script makes the Pi take a picture of the text. Then it uses Tesseract OCR to convert the image to plain text, and runs the text through a speech synthesis engine which reads it aloud. The reader is on as long as it’s plugged in, so it’s ready to work at the push of a button. We can probably all appreciate such a low-hassle design. Be sure to check out the demo after the break.
Stephen Hawking, although unable to speak himself, is immediately recognizable by his voice which is provided through a computer and a voice emulator. What may come as a surprise to some is that this voice emulator, the Emic2, has been used by many people, and is still around today and available for whatever text-to-speech projects you are working on. As a great example of this, [TegwynTwmffat] has built a weather forecasting station using an Emic2 voice module to provide audible weather alerts.
Besides the unique voice, the weather center is a high quality build on its own. An Arduino Mega 2560 equipped with a GPRS module is able to pull weather information once an hour. After the voice module was constructed (which seems like a project in itself) its relatively straightforward to pass the information from the Arduino over to the module and have it start announcing the weather. It can even be programmed to sing the weather to you!
All of the code that [TegwynTwmffat] used to build this is available on the project site if you’re curious about building your own Emic2 voice system. It’s also worth noting that GPRS is available to pretty much anyone and is a relatively simple system to start using to do things like pull weather information from, but you could also use it to roll out your own private cell phone network with the right equipment and licensing.
Speech synthesis is nothing new, but it has gotten better lately. It is about to get even better thanks to DeepMind’s WaveNet project. The Alphabet (or is it Google?) project uses neural networks to analyze audio data and it learns to speak by example. Unlike other text-to-speech systems, WaveNet creates sound one sample at a time and affords surprisingly human-sounding results.
Before you rush to comment “Not a hack!” you should know we are seeing projects pop up on GitHub that use the technology. For example, there is a concrete implementation by [ibab]. [Tomlepaine] has an optimized version. In addition to learning English, they successfully trained it for Mandarin and even to generate music. If you don’t want to build a system out yourself, the original paper has audio files (about midway down) comparing traditional parametric and concatenative voices with the WaveNet voices.
Another interesting project is the reverse path — teaching WaveNet to convert speech to text. Before you get too excited, though, you might want to note this quote from the read me file:
“We’ve trained this model on a single Titan X GPU during 30 hours until 20 epochs and the model stopped at 13.4 ctc loss. If you don’t have a Titan X GPU, reduce batch_size in the train.py file from 16 to 4.”
Last time we checked, you could get a Titan X for a little less than $2,000.
There is a multi-part lecture series on reinforced learning (the foundation for DeepMind). If you wanted to tackle a project yourself, that might be a good starting point (the first part appears below).