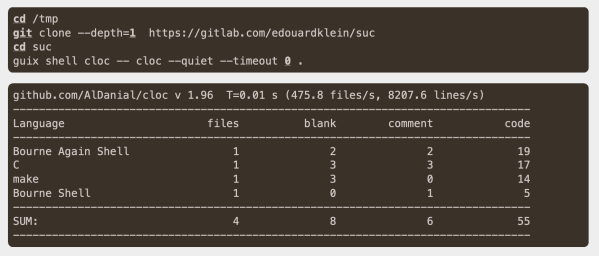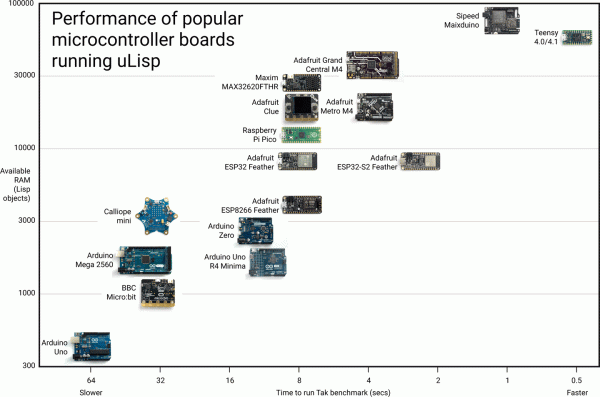
In a way it feels somewhat silly to market a version of Lisp as targeting resource-constrained platforms, considering the systems it ran on back in the 1960s, but as time goes on, what would have given 1970s Big Iron a run for its money is now a sub-$5 microcontroller that you can run uLisp (MicroLisp) on. This particular project now even has an ARM assembler that is written in Lisp whose source code (GitHub) fits on a mere two A4-sized pages.
ULisp currently supports five platforms, being AVR-nano (ATmega328 and similar low-cost AVRs), AVR, ARM, ESP (8266 and 32), as well as RISC-V. The purpose of this assembler is to execute native ARM instructions when running on an ARM board, since uLisp itself runs a Lisp interpreter on the platform. When executed natively like this, a considerable speed-up of the task can be expected, as illustrated by a number of ARM assembler examples in the documentation.
Running a Fibonacci sequence that takes 24.6 seconds with the Lisp version on an Adafruit Metro M4 is reduced to a mere 61 ms when ARM assembly is used instead. This shouldn’t be too shocking, since this assembler essentially bypasses the Lisp runtime, coming closer to what would be the performance of firmware written in e.g. C. However, it also demonstrates that with this ARM assembler it is possible to have your Lisp and still get native performance when you want it, all using Lisp code.