Last month, the GitHub repository for the popular program youtube-dl was taken down in response to a DMCA takedown notice filed by the Recording Industry Association of America (RIAA). The crux of the RIAA complaint was that the tool could be used to download local copies of music streamed from various platforms, a claim they said was supported by the fact that several copyrighted music files were listed as unit tests in the repository.
While many believed this to be an egregious misrepresentation of what the powerful Python program was really used for, the RIAA’s argument was not completely without merit. As such, GitHub was forced to comply with the DMCA takedown until the situation could be clarified. Today we’re happy to report that has happened, and the youtube-dl repository has officially been reinstated.
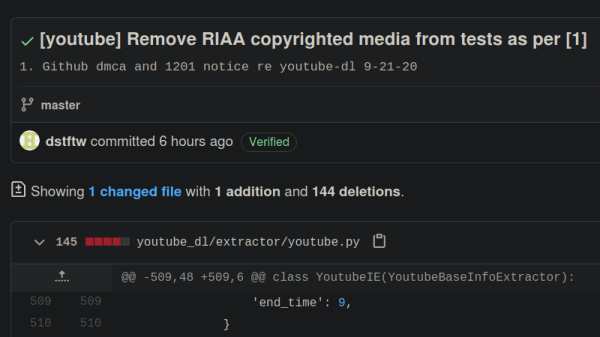
Represented by the Electronic Frontier Foundation, the current maintainers of youtube-dl made their case to GitHub’s DMCA agent in a letter this afternoon which explained how the tool worked and directly addressed the issue of copyrighted videos being used as test cases in the source code. They maintain that their program does not circumvent any DRM, and that the exchange between the client and server is the same as it would be if the user had viewed the resource with a web browser. Further, they believe that downloading a few seconds worth of copyrighted material for the purpose of testing the software’s functionality is covered under fair use. Even still, they’ve decided to remove all references to the songs in question to avoid any hint at impropriety.
Having worked closely with the youtube-dl developers during this period, GitHub released their own statement to coincide with the EFF letter. They explained that the nature of the RIAA’s original complaint forced their hand, but that they never believed taking down the repository was the right decision. Specifically, they point out the myriad of legitimate reasons that users might want to maintain local copies of streamed media. While GitHub says they are glad that this situation was resolved quickly, they’ll be making several changes to their internal review process to help prevent further frivolous takedowns. Specifically the company says they will work with technical and legal experts to review the source code in question before escalating any further, and that if there’s any ambiguity as to the validity of the claim, they’ll side with the developers.
The Internet was quick to defend youtube-dl after the takedown, and we’re happy to see that GitHub made good on their promises to work with the developers to quickly get the repository back online. While the nature of open source code meant that the community was never in any real danger of losing this important tool, it’s in everyone’s best interest that development of the project can continue in the open.