Having a history of shell commands is a great idea. It is, of course, enormously handy when you have to run something repetitively or you make a simple mistake that needs correction. However, as I’ve mentioned in the past, bash history isn’t without its problems. For one thing, by default, you don’t get history in one window from typing in another window. If you use a terminal multiplexer or a GUI, you are very likely to have many shells open. You can make them share history, but that comes with its own baggage. If you think about it, we have super fast computers with tons of storage compared to the “old days,” yet shell history is pretty much the same as it has been for decades. But [Rcaloras] did think about it and created Bashhub, a history database for bash, zsh, and probably some other shells, too.
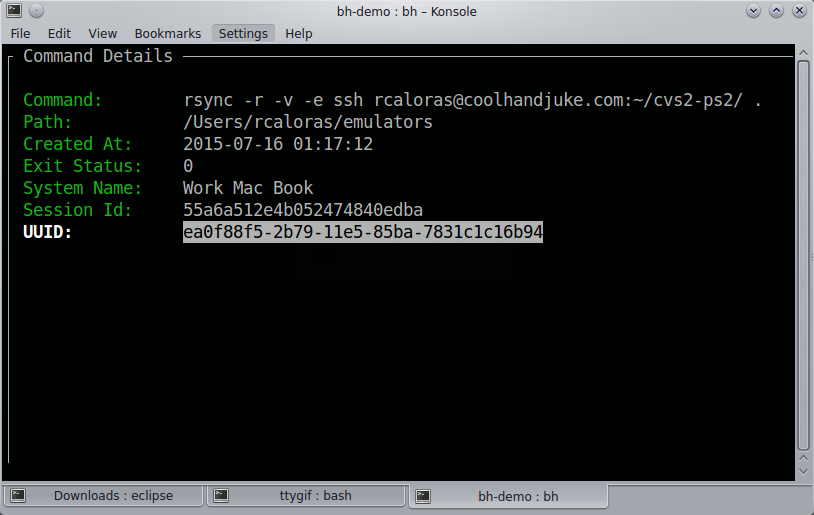
You might think you don’t need anything more than what you have, and, of course, you don’t. However, Bashhub offers privately stored and encrypted history across machines. It also provides context about commands you’ve executed in the past. In other words, you can see the directory you were in, the exact time and date, the system you were on, and the last return code of the command.