Color palettes are key to any sort of visual or graphic design. A designer has to identify a handful of key colours to make a design work, making calls on what’s eye catching or what sets the mood appropriately. One of the problems is that it relies heavily on subjective judgement, rather than any known mathematical formula. There are rules one can apply, but rules can also be artistically broken, so it’s never a simple task. To this end, [Jack Qiao] created colormind.io, a tool that uses neural nets to generate color palettes.
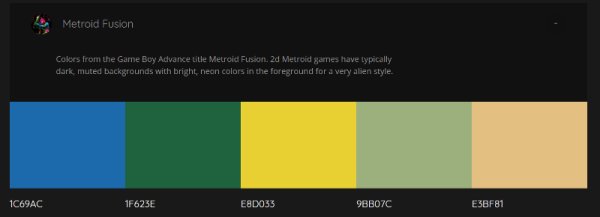
It’s a fun tool – there’s a selection of palettes generated from popular media and sunset photos, as well as the option to generate custom palettes yourself. Colours can be locked so you can iterate around those you like, finding others that match well. The results are impressive – the tool is able to generate palettes that seem to blend rather well. We were unable to force it to generate anything truly garish despite a few attempts!
The blog explains the software behind the curtain. After first experimenting with a type of neural net known as an LSTM, [Jack] found the results too bland. The network was afraid to be wrong, so would choose values very much “in the middle”, leading to muted palettes of browns and greys. After switching to a less accuracy-focused network known as a GAN, the results were better – [Jack] says the network now generates what it believes to be “plausible” palettes. The code has been uploaded to GitHub if you’d like to play around with it yourself.
Check out this primer on neural nets if you’d like to learn more. We’d like to know – how do you pick a palette when starting a project? Let us know in the comments.