A couple of decades ago one of *the* smartphone accessories to have was a Bluetooth keyboard which projected the keymap onto a table surface where letters could be typed in a virtual space. If we’re honest, we remember them as not being very good. But that hasn’t stopped the idea from resurfacing from time to time.
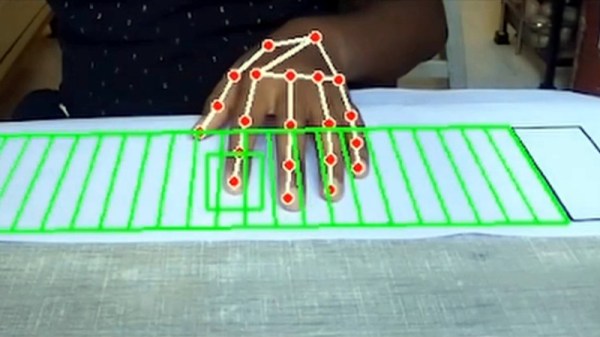
We’re reminded of it by [Mayuresh1611]’s paper piano, in which a virtual piano keyboard is watched over by a webcam to detect the player’s fingers such that the correct note from a range of MP3 files is delivered.
The README is frustratingly light on details other than setup, but a dive into the requirements reveals OpenCV as expected, and TensorFlow. It seems there’s a training step before a would-be virtual virtuoso can tinkle on the non-existent ivories, but the demo shows that there’s something playable in there. We like the idea, and wonder whether it could also be applied to other instruments such as percussion. A table as a drum kit would surely be just as much fun.
All of the machine language stuff coming out lately doesn’t affect you if you are developing with embedded microcontrollers, right? Perhaps not. Microsoft Research India wants you to use their EdgeML tool to do machine learning tasks such as gesture recognition in tiny devices like an Arduino Uno. According to the developers, you might need as little as 2 KB of RAM. There’s no network connection required and the work is using Tensorflow underneath, so it is compatible with much of what you’ll find for bigger computers.
If you add processing power, you can get more capability. For example, one of the demonstrations is a wake-word recognizer on a Raspberry Pi Zero (although the page for that demo seems to be missing at the moment; try the GesturePod, instead).
The system generally uses Python, but there are efficient C++ implementations for selected algorithms. The code lives on GitHub. There are also a number of research papers about each tool that you can find on the GitHub page. There’s also a recent paper on MinUn, an attempt to make things even more efficient for ARM microcontrollers. In particular, MinUn can store approximate numbers to save space, allows for variable precision of tensors, and tries to reduce memory fragmentation, an important feature for CPUs that don’t have memory management units.
If you haven’t studied TensorFlow yet, start here. Why use something like this with a microcontroller? How about smarter robots?
Issac Asimov foresaw 3D virtual meetings but gave them the awkward name “tridimensional personification.” While you could almost do this now with VR headsets and 3D cameras, it would be awkward at best. It is easy to envision conference rooms full of computer equipment and scanners, but an MIT student has a method that may do away with all that by using machine learning to simplify hologram generation.
As usual, though, the popular press may be carried away a little bit. The key breakthrough here is that you can use TensorFlow to generate real-time holograms at a few frames per second using consumer-grade processing power found in a high-end phone from images with depth information, which is also available on some phones. There’s still the problem of displaying the hologram on the other side, which your phone can’t do. So any implication that you’ll download an app that enables holograms phone calls is hyperbole and images of this are in the realm of photoshop.
[Vuong Nguyen] clearly knows his way around artificial intelligence accelerator hardware, creating ztachip: an open source implementation of an accelerator platform for AI and traditional image processing workloads. Ztachip (pronounced “zeta-chip”) contains an array of custom processors, and is not tied to one particular architecture. Ztachip implements a new tensor programming paradigm that [Vuong] has created, which can accelerate TensorFlow tasks, but is not limited to that. In fact it can process TensorFlow in parallel with non-AI tasks, as the video below shows.
A RISC-V core, based on the VexRiscV design, is used as the host processor handling the distribution of the application. VexRiscV itself is quite interesting. Written in SpinalHDL (a Scala variant), it’s super configurable, producing a Verilog core, ready to drop into the design.
A Digilent Arty-A7, Arducam and a VGA PMOD is all you need
From a hardware design perspective the RISC-V core hooks up to an AXI crossbar, with all the AXI-lite busses muxed as is usual for the AMBA AXI ecosystem. The Ztachip core as well as a DDR3 controller are also connected, together with a camera interface and VGA video.
Other than providing an FPGA-specific DDR3 controller and AXI crossbar IP, the rest of the design is generic RTL. This is good news. The demo below deploys onto an Artix-7 based Digilent (Arty-A7) with a VGA PMOD module, but little else needed. Pre-build Xilinx IP is provided, but targeting a different FPGA shouldn’t be a huge task for the experienced FPGA ninja.
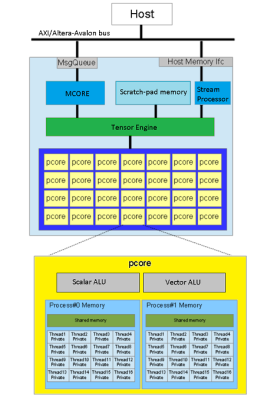
Ztachip top level architecture
The magic happens in the Ztachip core, which is mostly an array of Pcores. Each Pcore has both vector and scalar processing capability, making it super flexible. The Tensor Engine (internally this is the ‘dataplane processor’) is in charge here, sending instructions from the RISC-V core into the Pcore array together with image data, as well as streaming video data out. That camera is only a 0.3 MP Arducam, and the video is VGA resolution, but give it a bigger FPGA and those limits could be raised.
This domain-specific approach uses a highly modified C-like language (with a custom compiler) to describe the application that is to be distributed across the accelerator array. We couldn’t find any documentation on this, but there are a few example algorithms.
The demo video shows a real-time mix of four algorithms running in parallel; one object classification (Google’s Tensorflow mobilenet-ssd, a pre-trained AI model) canny edge detection, a Harris corner detection, and Optical flow which gives it a predator-like motion vision.
[Vuong] reckons, efficiency wise it is 5.5x more computationally efficient than a Jetson Nano and 37x more than Google’s TPU edge. These are bold claims, to say the least, but who are we to argue with a clearly incredibly talented engineer?
TensorFlow is a machine learning and AI library that has enabled so much and brought AI within the reach of most developers. But it’s fair to say that it’s not for the less powerful computers. For them there’s TensorFlow Lite, in which a model is created on a larger machine and exported to a microcontroller or similarly resource-constrained one. [Nick Bild] has probably taken this to its extreme though, by achieving this feat on a Commodore 64. Not just that, but he’s also done it using Commodore BASIC.
TensorFlow Lite works by the model being created as a C array which is then parsed and run by an interpreter on the microcontroller. This is a little beyond the capabilities of the mighty 64, so he has instead created a Python script that does the job of the interpreter and produces Commodore BASIC code that can run on the 64. The trusty Commodore was one of the more powerful home computers of its day, but we’re fairly certain that its designers never in their wildest dreams expected it to be capable of this!
“With the power of edge AI in the palm of your hand, your business will be unstoppable.”
That’s what the marketing seems to read like for artificial intelligence companies. Everyone seems to have cloud-scale AI-powered business intelligence analytics at the edge. While sounding impressive, we’re not convinced that marketing mumbo jumbo means anything. But what does AI on edge devices look like these days?
Being on the edge just means that the actual AI evaluation and maybe even fine-tuning runs locally on a user’s device rather than in some cloud environment. This is a double win, both for the business and for the user. Privacy can more easily be preserved as less information is transmitted back to a central location. Additionally, the AI can work in scenarios where a server somewhere might not be accessible or provide a response quickly enough.
Google and Apple have their own AI libraries, ML Kit and Core ML, respectively. There are tools to convert Tensorflow, PyTorch, XGBoost, and LibSVM models into formats that CoreML and ML Kit understand. But other solutions try to provide a platform-agnostic layer for training and evaluation. We’ve also previously covered Tensorflow Lite (TFL), a trimmed-down version of Tensorflow, which has matured considerably since 2017.
For this article, we’ll be looking at PyTorch Live (PTL), a slimmed-down framework for adding PyTorch models to smartphones. Unlike TFL (which can run on RPi and in a browser), PTL is focused entirely on Android and iOS and offers tight integration. It uses a react-native backed environment which means that it is heavily geared towards the node.js world.
Vizy is a Linux-based “AI camera” based on the Raspberry Pi 4 that uses machine learning and machine vision to pull off some neat tricks, and has a design centered around hackability. I found it ridiculously simple to get up and running, and it was just as easy to make changes of my own, and start getting ideas.
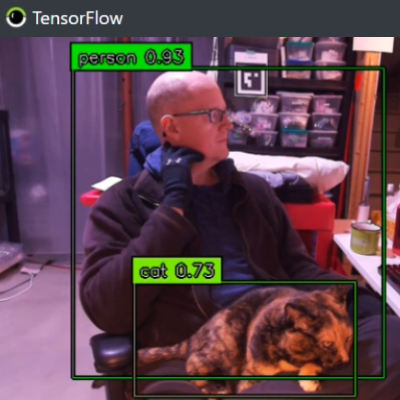
Out of the box, Vizy is only a couple lines of Python away from being a functional Cat Detector project.
I was running pre-installed examples written in Python within minutes, and editing that very same code in about 30 seconds more. Even better, I did it all without installing a development environment, or even leaving my web browser, for that matter. I have to say, it made for a very hacker-friendly experience.
Vizy comes from the folks at Charmed Labs; this isn’t their first stab at smart cameras, and it shows. They also created the Pixy and Pixy 2 cameras, of which I happen to own several. I have always devoured anything that makes machine vision more accessible and easier to integrate into projects, so when Charmed Labs kindly offered to send me one of their newest devices, I was eager to see what was new.
I found Vizy to be a highly-polished platform with a number of truly useful hardware and software features, and a focus on accessibility and ease of use that I really hope to see more of in future embedded products. Let’s take a closer look.