Recently Air Canada was in the news regarding the outcome of Moffatt v. Air Canada, in which Air Canada was forced to pay restitution to Mr. Moffatt after the latter had been disadvantaged by advice given by a chatbot on the Air Canada website regarding the latter’s bereavement fare policy. When Mr. Moffatt inquired whether he could apply for the bereavement fare after returning from the flight, the chatbot said that this was the case, even though the link which it provided to the official bereavement policy page said otherwise.
This latter aspect of the case is by far the most interesting aspect of this case, as it raises many questions about the technical details of this chatbot which Air Canada had deployed on its website. Since the basic idea behind such a chatbot is that it uses a curated source of (company) documentation and policies, the assumption made by many is that this particular chatbot instead used an LLM with more generic information in it, possibly sourced from many other public-facing policy pages.
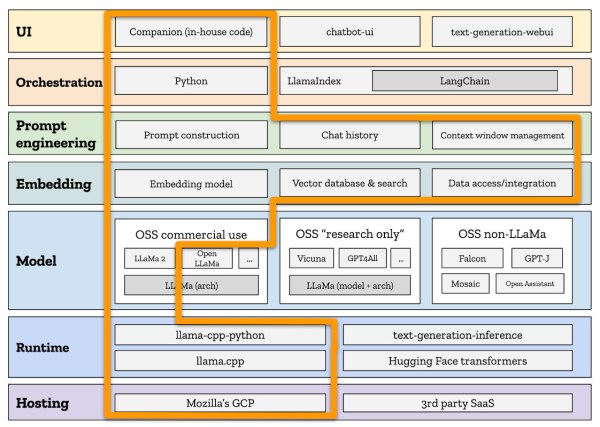
Whatever the case may be, chatbots are increasingly used by companies, but instead of pure LLMs they use what is called RAG: retrieval augmented generation. This bypasses the language model and instead fetches factual information from a vetted source of documentation.
Continue reading “Air Canada’s Chatbot: Why RAG Is Better Than An LLM For Facts”