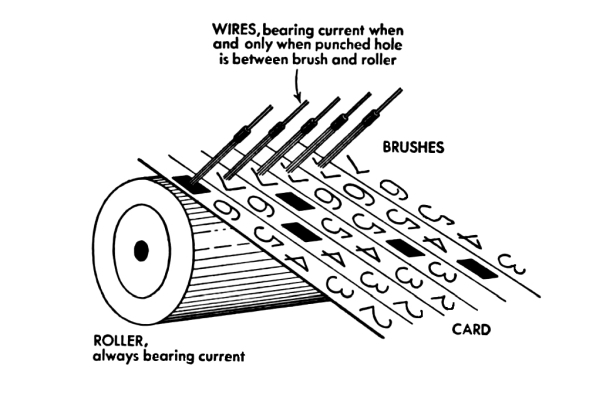
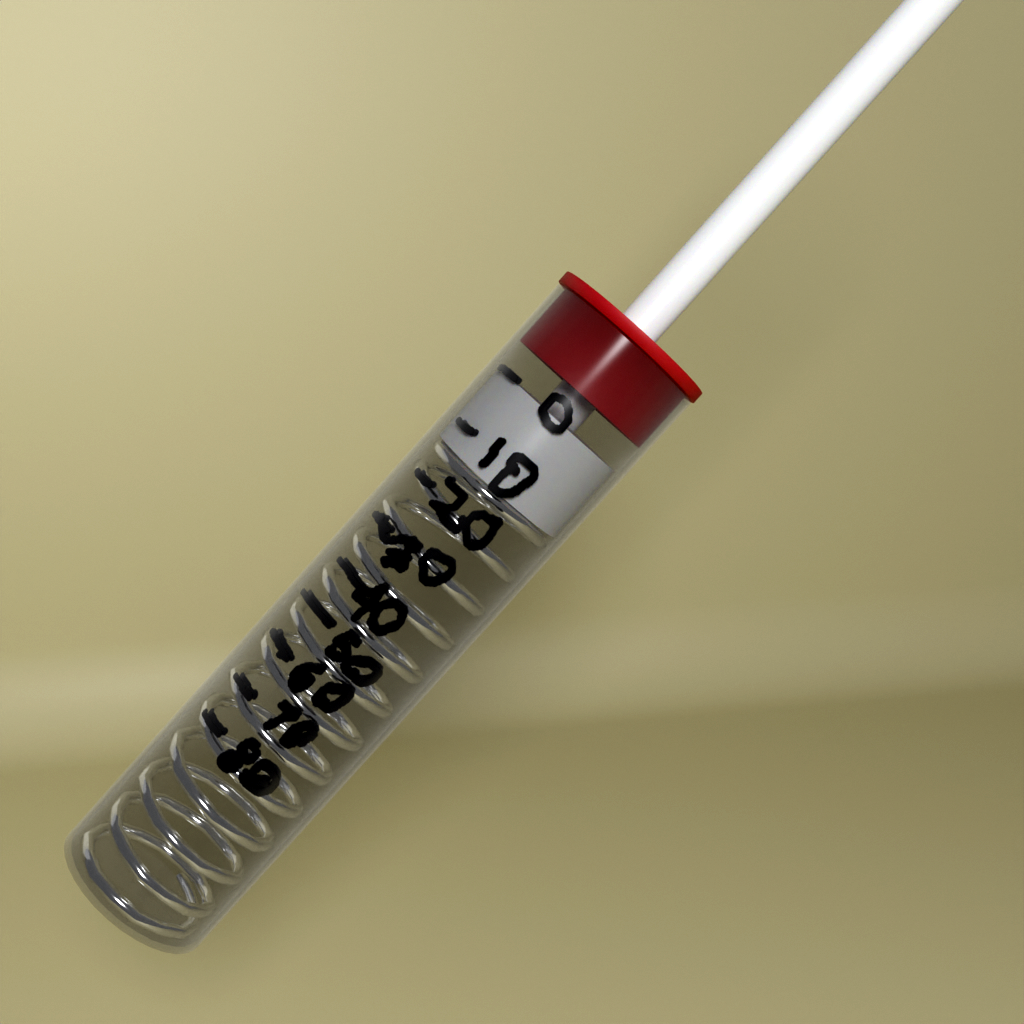
We see a lot of hacks where the path to success is pretty obvious, if maybe strewn with all sorts of complications, land-mines, and time-sinks. Then we get other hacks that are just totally out-of-the-box. Maybe the work itself isn’t so impressive, or even “correct” by engineering standards, but the inner idea that’s so crazy it just might work shines through.
 This week, for instance, we saw an adaptive backlight LED TV modification that no engineer would ever design. Whether it was just the easiest way out, or used up parts on hand, [Mousa] cracked the problem of assigning brightnesses to the LED backlights by taking a tiny screen, playing the same movie on it, pointing it at an array of light sensors, and driving the LEDs inside his big TV off of that. No image processing, no computation, just light hitting LDRs. It’s mad, and it involves many, many wires, but it gets the job done.
This week, for instance, we saw an adaptive backlight LED TV modification that no engineer would ever design. Whether it was just the easiest way out, or used up parts on hand, [Mousa] cracked the problem of assigning brightnesses to the LED backlights by taking a tiny screen, playing the same movie on it, pointing it at an array of light sensors, and driving the LEDs inside his big TV off of that. No image processing, no computation, just light hitting LDRs. It’s mad, and it involves many, many wires, but it gets the job done.
Similarly, we saw an answer to the wet-3D-filament problem that’s as simple as it could possibly be: basically a tube with heated, dry air running through it that the filament must pass through on it’s way to the hot end. We’ve seen plenty of engineered solutions to damp filament, ranging from an ounce of prevention in the form of various desiccant storage options, to a pound of cure – putting the spools in the oven to bake out. We’re sure that drying filament inline isn’t the right way to do it, but we’re glad to see it work. The idea is there when you need it.
Not that there’s anything wrong with the engineering mindset. Quite the contrary: most often taking things one reasonable step at a time, quantifying up all the unknowns, and thinking through the path of least resistance gets you to the finish line of your project faster. But we still have to admire the off-the-wall hacks, where the way that makes the most sense isn’t always the most beautiful way to go. It’s a good week on Hackaday when we get both types of projects in even doses.