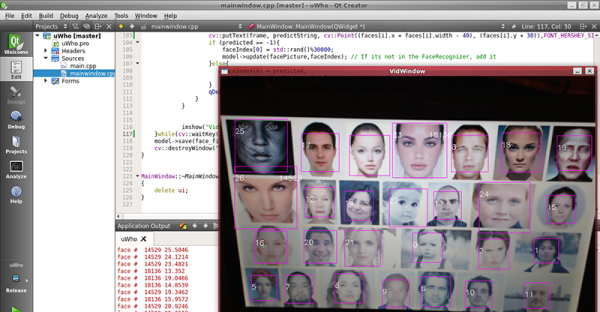
In a stiflingly hot lecture tent at CCCamp on Friday, Adam Harvey took to the stage to discuss the huge data sets being used by groups around the world to train facial recognition software. These faces come from a variety of sources and soon Adam and his research collaborator Jules LaPlace will release a tool that makes these dataset searchable allowing you to figure out if your face is among the horde.
Facial recognition is the new hotness, recently bubbling up to the consciousness of the general public. In fact, when boarding a flight from Detroit to Amsterdam earlier this week I was required to board the plane not by showing a passport or boarding pass, but by pausing in front of a facial recognition camera which subsequently printed out a piece of paper with my name and seat number on it (although it appears I could have opted out, that was not disclosed by Delta Airlines staff the time). Anecdotally this gives passengers the feeling that facial recognition is robust and mature, but Adam mentions that this not the case and that removed from highly controlled environments the accuracy of recognition is closer to an abysmal 2%.
Images are only effective in these datasets when the interocular distance (the distance between the pupils of your eyes) is a minimum of 40 pixels. But over the years this minimum resolution has been moving higher and higher, with the current standard trending toward 300 pixels. The increase is not surprising as it follows a similar curve to the resolution available from digital cameras. The number of faces available in data sets has also increased along a similar curve over the years.
Adam’s talk recounted the availability of face and person recognition datasets and it was a wild ride. Of note are data sets by the names of Brainwash Cafe, Duke MTMC (multi-tracking-multi-camera), Microsoft Celeb, Oxford Town Centre, and the Unconstrained College Students data set. Faces in these databases were harvested without consent and that has led to four of them being removed, but of course, they’re still available as what is once on the Internet may never die.
The Microsoft Celeb set is particularly egregious as it used the Bing search engine to harvest faces (oh my!) and has associated names with them. Lest you think you’re not a celeb and therefore safe, in this case celeb means anyone who has an internet presence. That’s about 10 million faces. Adam used two examples of past CCCamp talk videos that were used as a source for adding the speakers’ faces to the dataset. It’s possible that this is in violation of GDPR so we can expect to see legal action in the not too distant future.
Your face might be in a dataset, so what? In their research, Adam and Jules tracked geographic locations and other data to establish who has downloaded and is likely using these sets to train facial recognition AI. It’s no surprise that the National University of Defense Technology in China is among the downloaders. In the case of US intelligence organizations, it’s easier much easier to know they’re using some of the sets because they funded some of the research through organizations like the IARPA. These sets are being used to train up military-grade face recognition.
What are we to do about this? Unfortunately what’s done is done, but we do have options moving forward. Be careful of how you license images you upload — substantial data was harvested through loopholes in licenses on platforms like Flickr, or by agreeing to use through EULAs on platforms like Facebook. Adam’s advice is to stop populating the internet with faces, which is why I’ve covered his with the Jolly Wrencher above. Alternatively, you can limit image resolution so interocular distance is below the forty-pixel threshold. He also advocates for changes to Creative Commons that let you choose to grant or withhold use of your images in train sets like these.
Adam’s talk, MegaPixels: Face Recognition Training Datasets, will be available to view online by the time this article is published.

 In Ningbo, cameras oversee the intersections, and use facial-recognition to shame offenders by putting their faces up on large displays for all to see, and presumably mutter “tsk-tsk”. So it shocked Dong Mingzhu, the chairwoman of China’s largest air conditioner firm, to see her own face on the wall of shame when she’d done nothing wrong. The
In Ningbo, cameras oversee the intersections, and use facial-recognition to shame offenders by putting their faces up on large displays for all to see, and presumably mutter “tsk-tsk”. So it shocked Dong Mingzhu, the chairwoman of China’s largest air conditioner firm, to see her own face on the wall of shame when she’d done nothing wrong. The