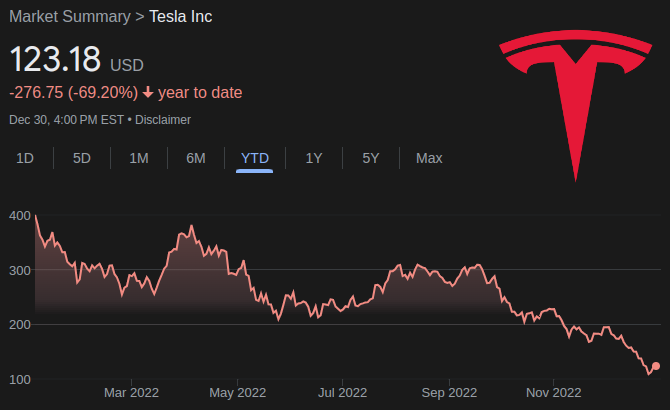
Well folks, we made it through another one. While it would be a stretch to call 2022 a good year for those of us in the hacking and making community, the light at the end of the tunnel does seem decidedly brighter now than it did this time 365 days ago. It might even be safe to show some legitimate optimism for the year ahead, but then again I was counting on my Tesla stocks to be a long-term investment, so what the hell do I know about predicting the future.
Thankfully hindsight always affords us a bit of wisdom, deservedly or otherwise. Now that 2022 is officially in the rearview mirror, it’s a good time to look back on the highs (and lows) of the last twelve months. Good or bad, these are the stories that will stick out in our collective minds when we think back on this period of our lives.
Oh sure, some might wish they could take the Men in Black route and forget these last few years ever happened, but it doesn’t work that way. In fact, given the tumultuous times we’re currently living in, it seems more likely than not that at some point we’ll find ourselves having to explain the whole thing to some future generation as they stare up at us wide-eyed around a roaring fire. Though with the way this timeline is going, the source of said fire might be the smoldering remains of an overturned urban assault robot that you just destroyed.
So while it’s still fresh in our minds, and before 2023 has a chance to impose any new disasters on us, let’s take a trip back through some of the biggest stories and themes of the last year.