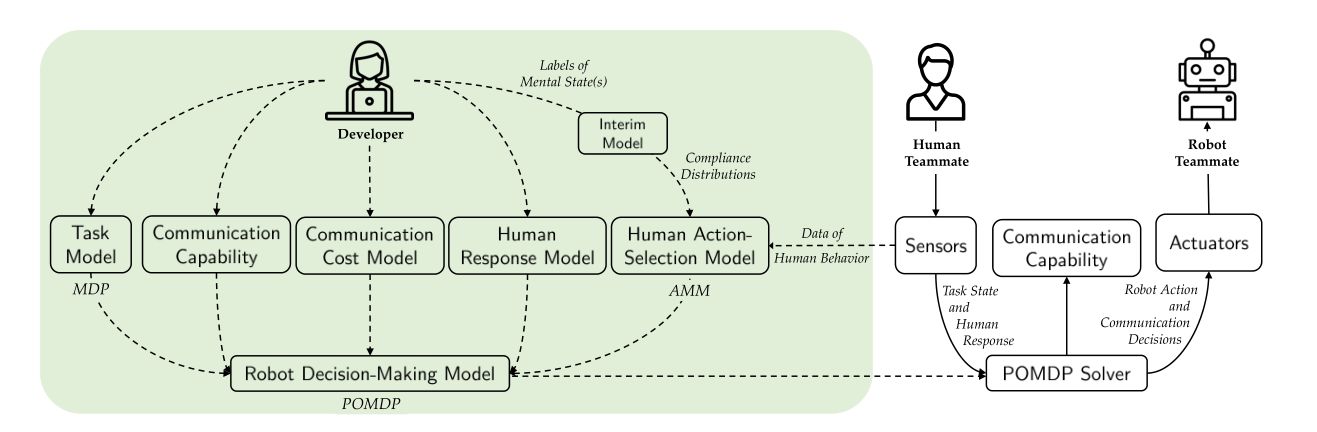
QR codes are a handy way to embed information, but they aren’t exactly pretty. New work from MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) have a new way to produce high contrast QR codes that are invisible. [PDF]
If this sounds familiar, you may remember CSAILs previous project embedding QR codes into 3D prints via IR-transparent filament. This followup to that research increases the detection of the objects by using an IR-fluorescent filament. Another benefit of this new approach is that while the InfraredTags could be any color you wanted as long as it was black, BrightMarkers can be embedded in objects of any color since the important IR component is embedded in traditional filament instead of the other way around.
One of the more interesting applications is privacy-preserving object detection since the computer vision system only “sees” the fluorescent objects. The example given is marking a box of valuables in a home to be detected by interior cameras without recording the movements of the home’s occupants, but the possibilities certainly don’t end there, especially given the other stated application of tactile interfaces for VR or AR systems.
We’re interested to see if the researchers can figure out how to tune the filament to fluoresce in more colors to increase the information density of the codes. Now, go forth and 3D print a snake with snake in a QR code inside!
Continue reading “Fluorescent Filament Makes Object Identification Easier”