80s-era electronic speech certainly has a certain retro appeal to it, but it can sometimes be a useful data output method since it can be implemented on very little hardware. [luc] demonstrates this with a talking thermometer project that requires no display and no special hardware to communicate temperatures to a user.
Back in the day, there were chips like the Votrax SC-01A that could play phonemes (distinct sounds that make up a language) on demand. These would be mixed and matched to create identifiable words, in that distinctly synthesized Speak & Spell manner that is so charming-slash-uncanny.

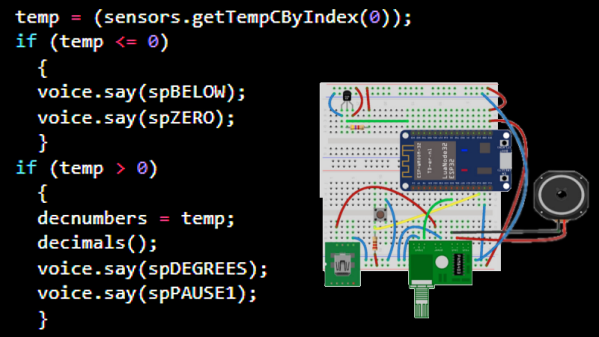
Nowadays, even hobbyist microcontrollers have more than enough processing power and memory to do a similar job entirely in software, which is exactly what [luc]’s talking thermometer project does. All this is done with the Talkie library, originally written for the Arduino and updated for the ESP32 and other microcontrollers. With it, one only needs headphones or a simple audio amplifier and speaker to output canned voice data from a project.
[luc] uses it to demonstrate how to communicate to a user in a hands-free manner without needing a display, and we also saw this output method in an electric unicycle which had a talking speedometer (judged to better allow the user to keep their eyes on the road, as well as minimizing the parts count.)
Would you like to listen to an authentic, somewhat-understandable 80s-era text-to-speech synthesizer? You’re in luck, because we can show you an authentic vintage MicroVox unit in action. Give it a listen, and compare it to a demo of the Talkie library in the video below.
Continue reading “Make Your ESP32 Talk Like It’s The 80s Again”