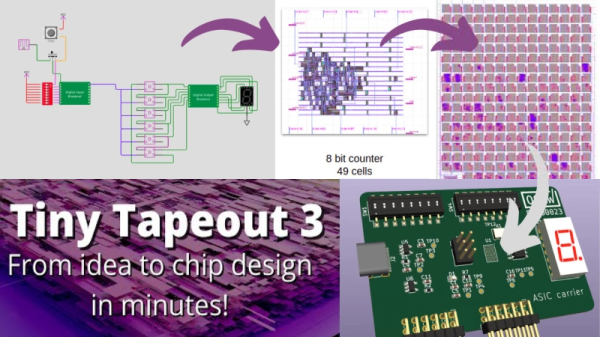
Custom semiconductor chips are generally big projects made by big companies with big budgets. Thanks to Tiny Tapeout, students, hobbyists, or anyone else can quickly get their designs onto an actual fabricated chip. [Matt Venn] has announced the opening of a third round of the Tiny Tapeout project for March 2023.
In 2022, Tiny Tapeout 1 piloted fabrication of user designs onto custom chips referred to as application-specific integrated circuits or ASICs. Following success of the pilot round, Tiny Tapeout 2 became the first paid version delivering guaranteed silicon. For Tiny Tapeout 2, there were 165 submissions. Most submissions were designed using a hardware description language such as Verilog or Amaranth, but ASICs can also be designed in the visual schematic capture tool Wokwi.
Each submitted design must fit within 150 by 170 microns. That footprint can accommodate around one thousand standard cells, which is certainly enough to explore a digital system of real interest. Examples from Tiny Tapeout 2 include digital neurons, FPGAs, and RISC-V processor cores.
Once the 250 designs are submitted, they’ll be combined into a large grid along with a controller. The controller will receive input signals and pump the inputs via a scan chain through the entire grid to each design. The results from each design continue through the scan chain to be output from the grid. Since all 250 designs will be combined on to one chip, each designer will receive everybody else’s design along with their own. This shared process opens a huge opportunity for experimentation.
To get started on your own ASIC design right away, visit Tiny Tapeout. Also check out the talk [Matt] gave at Supercon 2022: Bringing Chip Design to the Masses along with his Zero to ASIC videos. And we’re not saying anything official, but he’ll probably be giving a workshop at Hackaday Berlin.
Continue reading “Tiny Tapeout 3: Get Your Own Chip Design To A Fab” →