This week Jonathan chats with Andrea Gallo about RISC-V! What does it mean for RISC-V to be an Open ISA? Where is RISC-V popping up, and what’s the new frontier? Watch to find out!
Continue reading “FLOSS Weekly Episode 874: Really, We Do PDFs”

This week Jonathan chats with Andrea Gallo about RISC-V! What does it mean for RISC-V to be an Open ISA? Where is RISC-V popping up, and what’s the new frontier? Watch to find out!
Continue reading “FLOSS Weekly Episode 874: Really, We Do PDFs”

 Even with Amazon’s Echo Show devices running Linux in the form of the Android-derived FireOS, using them for non-Amazon approved purposes can be a chore at best. In the case of the Echo Show 8 even simple workarounds using ADB and the bootloader have been locked-down, requiring more drastic measures. Here [Vowed] over at the XDA forums shows off one such hack, involving directly tapping into the device’s eMMC.
Even with Amazon’s Echo Show devices running Linux in the form of the Android-derived FireOS, using them for non-Amazon approved purposes can be a chore at best. In the case of the Echo Show 8 even simple workarounds using ADB and the bootloader have been locked-down, requiring more drastic measures. Here [Vowed] over at the XDA forums shows off one such hack, involving directly tapping into the device’s eMMC.
Suffice it to say that this is not a hack for the faint of heart, with even the iFixit teardown guide for this device being rather daunting. Even after you get access to the mainboard, you still have to remove or cut open the metal can that covers the eMMC, so that you can unleash an eMMC programmer on it. It’s best to make sure to make a backup image of the original contents too, just in case you have to restore things.
With the shield out of the way you can solder fine wires to pads that connect to the eMMC to program it. You also have to solder wires to pads for the UART, though if you’re fancy you can also create a custom pogo pin adapter. With a serial connection established to the original firmware you can then enable features like ADB, and courtesy of the connected eMMC adapter it’s possible to directly alter system files to make rooting as easy as possible.
In addition to rooting the system you can also do a straight replacement of the eMMC contents, such as the demonstrated Debian installation. Even if not the most easy of mods, it’s good to see that it’s possible to repurpose these devices.
(Top image: Amazon Echo Show 8 3rd generation mainboard. Credit: iFixit, CC BY-NC-SA 3.0.)

I’ll admit it: I miss the simplicity of /etc/hosts. There was something elegant about it. You wanted laserprinter to mean 192.168.1.40, so you opened a text file and wrote:
192.168.1.40 laserprinter
Done. No cloud account, no discovery daemon, no dashboard with material-themed icons. Just a name and an address. The trouble, of course, is that /etc/hosts is only simple when you have one machine. The moment you have a desktop, a laptop, a Raspberry Pi, a NAS, a test box, and a phone or two, every little network change becomes a tiny distributed-database problem. Which copy of /etc/hosts is authoritative? Did you update the laptop? What about the machine you only boot once a month?
Modern LANs solved this with mDNS, using Avahi on Linux. It resolves addresses that end in .local. Instead of asking a central DNS server “who is thing.local?”, a machine sends a multicast query on the local network: “who has thing.local?” The device that owns the name answers. This is why your Linux box named spock and usually be reached as spock.local on your LAN.
There are limits. mDNS is link-local; it is meant for the local LAN, not the whole Internet and shouldn’t route across subnets. Each device is supposed to publish its own name. That works fine when the device cooperates. But what about devices that do not publish mDNS? Or little embedded things that barely even have an IP address?
That is where I wanted the best of both worlds: keep a small authoritative /etc/hosts file on one Linux box, but publish selected entries onto the LAN using mDNS.

You almost certainly don’t have an application for the sort of accurate timekeeping that’s made possible by this enhanced version of [Cristiano Monteiro]’s satellite-backed time server. By his own admission, the vast majority of users will be more than happy to have their system’s time synchronized by the traditional Network Time Protocol (NTP). But if you’re really chasing those last few microseconds, that’s where the Precision Time Protocol (PTP) comes in.
With NTP, you can get within 10 milliseconds or so of your upstream time source — but PTP is accurate down to nanoseconds. Unless you’re performing some kind of scientific research, running a robotic assembly line, or perhaps doing high-speed financial trading, there’s no reason for this level of accuracy. In fact, PTP is such a niche technology that until the release of the ESP32-P4, [Cristiano] couldn’t even find an affordable enough chip that supported it.
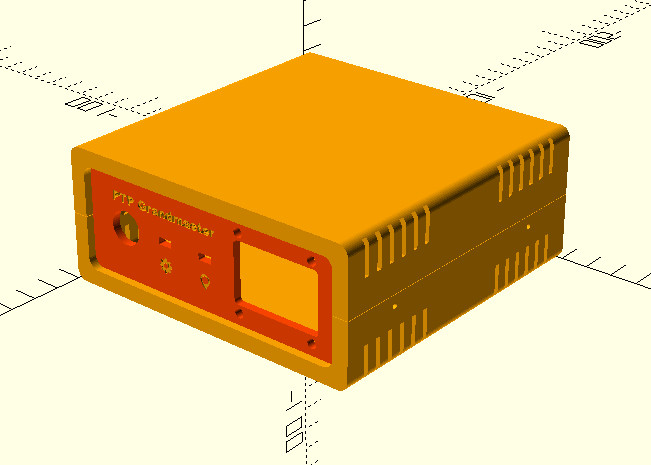 Hardware-level support for PTP is important as there’s no way to achieve this level of accuracy with software alone, the capability needs to be baked into the Ethernet controller. As you might expect, it takes a highly accurate time source to make the most of PTP, and that’s where the navigation-grade Global Navigation Satellite System (GNSS) receiver comes in. All told the cost of the build is unsurprisingly higher than that of its predecessor, but [Cristiano] says it’s still a couple zeros shy of what a commercial offering would run.
Hardware-level support for PTP is important as there’s no way to achieve this level of accuracy with software alone, the capability needs to be baked into the Ethernet controller. As you might expect, it takes a highly accurate time source to make the most of PTP, and that’s where the navigation-grade Global Navigation Satellite System (GNSS) receiver comes in. All told the cost of the build is unsurprisingly higher than that of its predecessor, but [Cristiano] says it’s still a couple zeros shy of what a commercial offering would run.
As with his original time server from 2021, [Cristiano] made sure this build was as friendly as possible for hackers and makers. We especially like the 3D printed case designed in OpenSCAD, and his insistence that the gadget have a front panel with blinking status LEDs. Again, the vast majority of us don’t need our clocks to be accurate down to the nanosecond…but it’s nice to know we have the option.

We know, we know. Despite being called ESP32-Plane-Radar, this project from [Mateusz Juszczyk] isn’t actually using radar. But thanks to the round LCD this desktop gadget does a fantastic job of recreating a classic radar display, and by pulling in Automatic Dependent Surveillance–Broadcast (ADS-B) data, the visuals even match nearby real-world aircraft.
 Perhaps the best part of this project is just how easy it is for others to get in on the action. Although the presentation certainly looks professional — and expensive, if we’re being honest — there’s nothing particularly exotic going on here. Specifically, there’s ESP32-C3 Super Mini behind the scenes cranking through the ADS-B data and pushing it out to a circular GC9A01 display. A minimalistic 3D printed enclosure holds both components, and while it’s undeniably slick as-is, we can’t help but think there’s potential here for more elaborate designs.
Perhaps the best part of this project is just how easy it is for others to get in on the action. Although the presentation certainly looks professional — and expensive, if we’re being honest — there’s nothing particularly exotic going on here. Specifically, there’s ESP32-C3 Super Mini behind the scenes cranking through the ADS-B data and pushing it out to a circular GC9A01 display. A minimalistic 3D printed enclosure holds both components, and while it’s undeniably slick as-is, we can’t help but think there’s potential here for more elaborate designs.
As you probably guessed from the lack of a radio in the parts list, the code [Mateusz] provides doesn’t actually sniff ADS-B out of the air. It connects to the local network over WiFi, and then hits adsb.fi to pull in crowdsourced flight data. Since the device has to connect to the network anyway, the code also offers up a web-based configuration interface which puts a little more polish on what’s already an impressive presentation.
We used a round GC9A01 display on the Vectorscope back in 2023, so if anyone ports this over to their old Supercon badge we’d love to see it in action.
Thanks to [Mauricio] for the tip.

Among the many forgotten might-have-beens of the games console world, the Atari Jaguar occupies a special place. It was the final gasp of Atari Corporation, the Jack Tramiel-era incarnation of the famous pioneering game console brand that brought us the ST line of computers, and like Marlon Brando’s Terry Malloy character from On the Waterfront, it coulda been a contender. But the early ’90s games business wasn’t kind to the console from Sunnyvale, and it was squeezed from behind by the SNES and Genesis/MegaDrive, and in front from the PlayStation. Thirty years later then, can it run Linux? [Cakehonolulu] is here to show us how.
With only 2 megabytes of RAM and space for 8 megabytes of ROM, this is hardly a powerhouse. But its 16-bit 68000 processor is a supported Linux architecture, albeit with the -nommu flag on compilation. The “Jerry” DSP chip has the required serial port and timer to boot a first Linux kernel, and after a bit of hackery to make it jump to the ROM location, something boots. There’s no init process until the flat executable file for a -nommu kernel is navigated, but with that past a BusyBox userspace and a graphics driver for the “Tom” graphics chip gives it a chunky on-screen console. The code can be found in a GitHub repository, for the curious.
It seems to be the moment for 68k consoles to receive the Linux treatment, as it’s only a few weeks since we saw it on a MegaDrive. Other ’90s consoles aren’t far behind though, with the Nintendo 64 falling to the penguin a few years ago. Meanwhile, the Dreamcast had Linux running decades ago.
Jaguar image: Evan-Amos, Public domain.

In the early 1990s, Don’t Copy That Floppy was an anti-piracy campaign that attempted to connect with computer-savvy youth through the power of hip-hop. While somewhat difficult to imagine given our current draconian Digital Rights Management (DRM) hellscape, warning kids about the potential legal ramifications of duplicating floppy disks containing copyrighted software was seen as necessary since at the time there was usually nothing preventing users from simply copying the contents of one disk to another.
Unfortunately 30+ years down the road, we’re now finding that somebody really should have been backing up some of those disks. Which is why the University of Cambridge of launched the Future Nostalgia project and produced Copy That Floppy! — a phenomenal guide on preserving the contents of floppy disks while we still can.
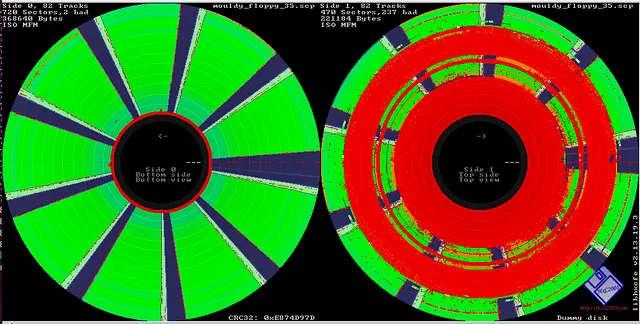
There’s no telling how much data could potentially be lost to time because its stuck on such an antiquated and fragile storage media, and the situation only gets worse with the passage of time. The problem isn’t just that modern computers don’t have floppy drives. The disks themselves degrade with age, a process which is accelerated if they aren’t stored properly.
As such, Copy That Floppy! only briefly touches on the most ideal situation — that is, buying a USB floppy drive and making copies of the bog standard 3.5 inch disks you might come across. It then moves right on into more advanced topics, such as interfacing with less common drive types, how to safely clean floppies, and the use of advanced tools such as Greaseweazle to analyze captured disk images.
We’ve seen demonstrations of some of these techniques before, and a few years back Adafruit got interested in floppy preservation with modern hardware. But in-depth guides like these that pull all that information together into one place are valuable resources.









