An enduring memory for most who used the 8-bit home computers of the early 1980s is the use of cassette tapes for program storage. Only the extremely well-heeled could afford a disk drive, so if you didn’t fancy the idea of waiting an eternity for your code to load then you were out of luck. If you had a Sinclair Spectrum though, by 1983 you had another option in the form of the unique Sinclair ZX Microdrive.
This was a format developed in-house by Sinclair Research that was essentially a miniaturized version of the endless-loop tape carts which had appeared as 8-track Hi-Fi cartridges in the previous decade, and promised lightning fast load times of within a few seconds along with a relatively huge storage capacity of over 80 kB. Sinclair owners could take their place alongside the Big Boys of the home computer world, and they could do so without breaking the bank too much.
The big news this week is the huge flaw in Microsoft’s Active Directory, CVE-2020-1472 (whitepaper). Netlogon is a part of the Windows domain scheme, and is used to authenticate users without actually sending passwords over the network. Modern versions of Windows use AES-CFB8 as the cryptographic engine that powers Netlogon authentication. This peculiar mode of AES takes an initialization vector (IV) along with the key and plaintext. The weakness here is that the Microsoft implementation sets the IV to all zeros.
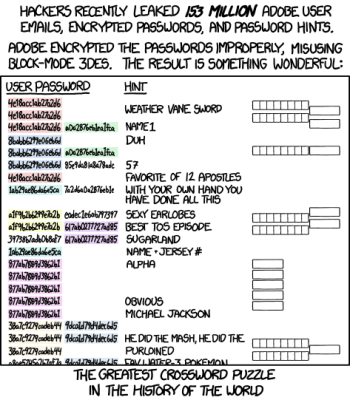
XKCD.com CC BY-NC 2.5
It’s worth taking a moment to cover why IVs exist, and why they are important. The basic AES encryption process has two inputs: a 128 bit (16 byte) plaintext, and a 128, 192, or 256 bit key. The same plaintext and key will result in the same ciphertext output every time. Encrypting more that 128 bits of data with this naive approach will quickly reveal a problem — It’s possible to find patterns in the output. Even worse, a clever examination of the patterns could build a decoding book. Those 16 byte patterns that occur most often would be guessed first. It would be like a giant crossword puzzle, trying to fill in the gaps.
This problem predates AES by many years, and thankfully a good solution has been around for a long time, too. Cipher Block Chaining (CBC) takes the ciphertext output of each block and mixes it (XOR) with the plaintext input of the next block before encrypting. This technique ensures the output blocks don’t correlate even when the plaintext is the same. The downside is that if one block is lost, the entire rest of the data cannot be decrypted Update: [dondarioyucatade] pointed out in the comments that it’s just the next block that is lost, not the entire stream. You may ask, what is mixed with the plaintext for the first block? There is no previous block to pull from, so what data is used to initialize the process? Yes, the name gives it away. This is an initialization vector: data used to build the initial state of a crypto scheme. Generally speaking, an IV is not secret, but it should be randomized. In the case of CBC, a non-random IV value like all zeros doesn’t entirely break the encryption scheme, but could lead to weaknesses. Continue reading “This Week In Security: AD Has Fallen, Two Factor Flaws, And Hacking Politicians”→
In 2018, the Camp Fire devastated a huge swathe of California, claiming 85 lives and costing 16.65 billion dollars. Measured in terms of insured losses, it was the most expensive natural disaster of the year, and the 13th deadliest wildfire in recorded history.
The cause of the fire was determined to be a single failed component on an electrical transmission tower, causing a short circuit and throwing sparks into the dry brush below – with predictable results. The story behind the failure was the focus of a Twitter thread by [Tube Time] this week, who did an incredible job of illuminating the material evidence that shows how the disaster came to be, and how it could have been avoided.
Mismanagement and Money
The blame for the incident has been laid at the feet of Pacific Gas and Electric, or PG&E, who acquired the existing Caribou-Palermo transmission line when it purchased Great Western Power Company back in 1930. The line was originally built in 1921, making the transmission line 97 years old at the time of the disaster. Despite owning the line for almost a full century, much of the original hardware was not replaced in the entire period of PG&Es ownership. Virtually no records were created or kept, and hardware from the early 20th century was still in service on the line in 2018.
Back in 2018, Microsoft began Project Natick, deploying a custom-designed data center to the sea floor off the coast of Scotland. Aiming to determine whether the underwater environment would bring benefits to energy efficiency, reliability, and performance, the project was spawned during ThinkWeek in 2014, an event designed to share and explore unconventional ideas.
This week, Microsoft reported that the project had been a success. The Northern Isles data center was recently lifted from the ocean floor in a day-long operation, and teams swooped in to analyse the hardware, and the results coming out of the project are surprisingly impressive.
Since the widespread manufacture of plastics began in earnest in the early 1950s, plastic pollution in the environment has become a major global problem. Nowhere is this more evident than the Great Pacific Garbage Patch. A large ocean gyre that has become a swirling vortex full of slowly decaying plastic trash, it has become a primary target for ocean cleanup campaigns in recent years.
However, plastic just doesn’t magically appear in the middle of the ocean by magic. The vast majority of plastic in the ocean first passes through river systems around the globe. Thanks to new research, efforts are now beginning to turn to tackling the issue of plastic pollution before it gets out to the broader ocean, where it can be even harder to clean up. Continue reading “Targeting Rivers To Keep Plastic Pollution Out Of The Ocean”→
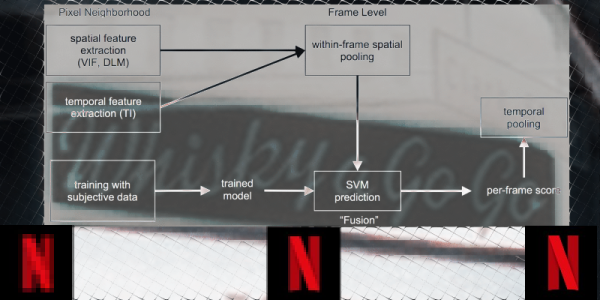
Netflix has recently announced that they now stream optimized shot-based encoding content for 4K. When I read that news title I though to myself: “Well, that’s great! Sounds good but… what exactly does that mean? And what’s shot-based encoding anyway?”
Later this month, people who use GitHub may find themselves suddenly getting an error message while trying to authenticate against the GitHub API or perform actions on a GitHub repository with a username and password. The reason for this is the removal of this authentication option by GitHub, with a few ‘brown-out’ periods involving the rejection of passwords to give people warning of this fact.
This change was originally announced by GitHub in November of 2019, had a deprecation timeline assigned in February of 2020 and another blog update in July repeating the information. As noted there, only GitHub Enterprise Server remains unaffected for now. For everyone else, as of November 13th, 2020, in order to use GitHub services, the use of an OAuth token, personal token or SSH key is required.
While this is likely to affect a fair number of people who are using GitHub’s REST API and repositories, perhaps the more interesting question here is whether this is merely the beginning of a larger transformation away from username and password logins in services.