Disney is working on modular, intelligent robot limbs that snap into place with magnets. The intelligence comes from a reasonable sized neural network that also incorporates some modularity. The robot is their Snapbot whose base unit can fit up to eight of limbs, and so far they’ve trained with up to three together.
The modularity further extends to a choice of three types of limb. One with roll and pitch, another with yaw and pitch, and a third with roll, yaw, and pitch. Interestingly, of the three types, the yaw-pitch one seems most effective.
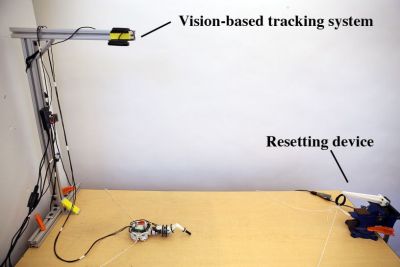 In this age of massive, deep neural networks requiring GPUs or even online services for training in a reasonable amount of time, it’s refreshing to see that this one’s only two layers deep and can be trained in three hours on a single-core, 3.4 GHz Intel i7 processor. Three hours may still seem long, but remember, this isn’t a simulation in a silicon virtual world. This is real-life where the servo motors have to actually move. Of course, they didn’t want to sit around and reset it after each attempt to move across the table so they built in an automatic mechanism to pull the robot back to the starting position before trying to cross the table again. To further speed training, they found that once they’d trained for one limb, they could then copy the last of the network’s layers to get a head starting on the training for two limbs.
In this age of massive, deep neural networks requiring GPUs or even online services for training in a reasonable amount of time, it’s refreshing to see that this one’s only two layers deep and can be trained in three hours on a single-core, 3.4 GHz Intel i7 processor. Three hours may still seem long, but remember, this isn’t a simulation in a silicon virtual world. This is real-life where the servo motors have to actually move. Of course, they didn’t want to sit around and reset it after each attempt to move across the table so they built in an automatic mechanism to pull the robot back to the starting position before trying to cross the table again. To further speed training, they found that once they’d trained for one limb, they could then copy the last of the network’s layers to get a head starting on the training for two limbs.
Why do training? Afterall, we’ve seen pretty awesome multi-limbed robots working with manual coding, an example being this hexapod tank based on one from the movie Ghost in the Shell. They did that too and then compared the results of the manual approach with those of the trained one and the trained one moved further in the same amount of time. At a minimum, we can learn a trick or two from this modular crawler.
Check out their article for the details and watch it in action in its learning environment below.
Continue reading “Disney’s New Robot Limbs Trained Using Neural Networks”





 You’ll need a few hundred images of your objects. These can either be scraped from an online source like Google’s images or you get take your own photos. If you use the latter approach, make sure to shoot from various angles, rotations, and with different lighting conditions. Fill your background with various other things and even have some things partially obscuring your objects. This may sound like a long, tedious task, but it can be done efficiently. [Edje Electronics] is working on recognizing playing cards so he first sprinkled them around his living room, added some clutter, and walked around, taking pictures using his phone. Once uploaded, some easy-to-use software helped him to label them all in around an hour. Note that he trained on 24 different objects, which are the number of different cards you get in a
You’ll need a few hundred images of your objects. These can either be scraped from an online source like Google’s images or you get take your own photos. If you use the latter approach, make sure to shoot from various angles, rotations, and with different lighting conditions. Fill your background with various other things and even have some things partially obscuring your objects. This may sound like a long, tedious task, but it can be done efficiently. [Edje Electronics] is working on recognizing playing cards so he first sprinkled them around his living room, added some clutter, and walked around, taking pictures using his phone. Once uploaded, some easy-to-use software helped him to label them all in around an hour. Note that he trained on 24 different objects, which are the number of different cards you get in a