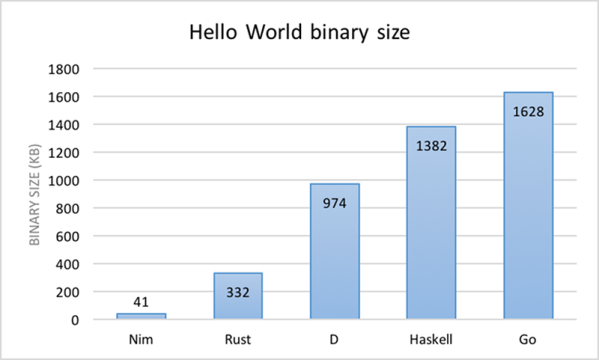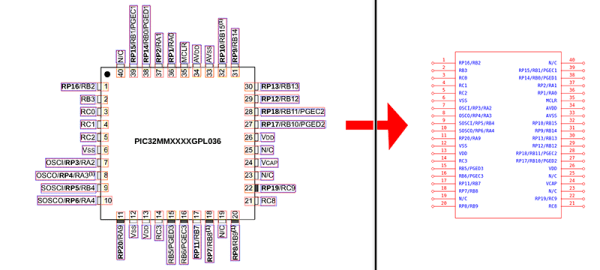
For anyone out there who has ever struggled finding a part for Eagle or KiCad, there are some who would say you’re doing it wrong. You’re supposed to make your own parts if you can’t find them in the libraries you already have. This is really the only way; PCB design tools are tools, and so the story goes you’ll never be a master unless you can make your own parts.
That said, making schematic parts and footprints is a pain, and if there’s a tool to automate the process, we’d be happy to use it. That’s exactly what uConfig does. It automatically extracts pinout information from a PDF datasheet and turns it into a schematic symbol.
uConfig is an old project from [sebastien caux] that’s been resurrected and turned into an Open Source tool. It works by extracting blocks of text from a PDF, sorts out pin numbers and pin labels, and associates those by the relevant name to make pins. It’s available as a pre-built project (for Windows, even!), and works kind of like magic.
The video demo below shows uConfig importing a PDF datasheet — in this case a PIC32 — automatically extracting the packages from the datasheet, and turning that into a schematic symbol. It even looks as if it’ll work, too. Of course, this is just the schematic symbol, not the full part including a footprint, but when it comes to footprints we’re probably dealing with standard packages anyway. If you’re looking to build a software tool that takes a datasheet and spits out a complete part, footprint and all, this is the place to start.
Continue reading “Creating KiCad Parts From A PDF Automagically”